
如何实现高性能延时消息
延时消息使用场景
需要某些事件在特定的时间点上触发时,就需要用到延时消息。
如何实现
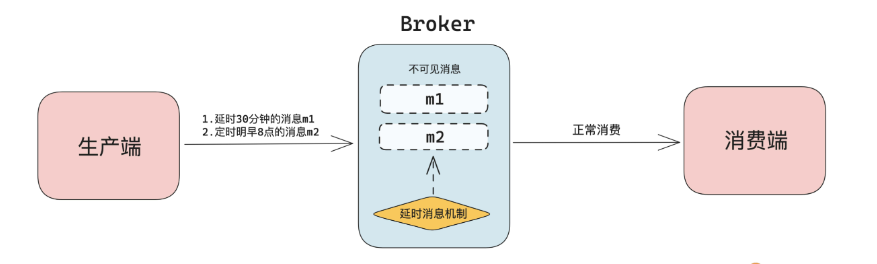
延时消息可以通过定时扫描来实现,但是资源浪费太多。
如果使用消息队列,可以理解为生产者生产一条消息,但是并不会被消费者看到,当到达固定的时间点后,消费者才能够看到并且消费消息。所以从技术上来看,消息队列实现延时消息主要包含数据存储、如何让消息可见、定时机制、主动推送四个部分。
以下主要介绍消息可见和定时机制。
如何让消息可见
让消息从不可见变为可见的思路:先将数据写入到临时存储,然后根据一定机制在数据到期后让消费端可以看到该消息。
临时存储大多有以下三种选择:
单独设计的数据结构
独立的 Topic
本地的某个存储引擎(如 RocksDB、Mnesia 等)
延时到期后,消费者如何得知该消息可以消费,有以下两种实现:
- 定时检测写入
- 消费时判断是否可见
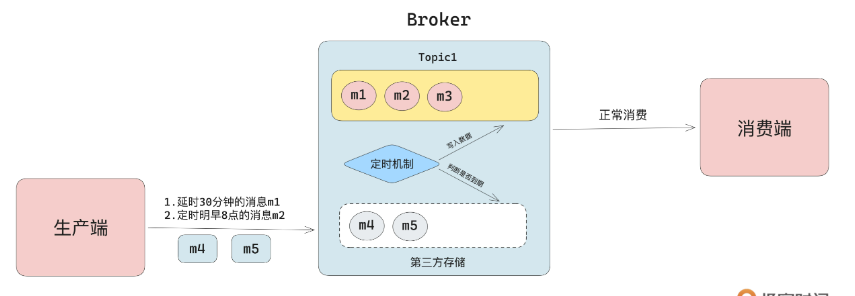
定时检测写入:指的是先将消息写入某个地方,同时有独立的线程去判断数据是否到期,如果到期则将数据写入真正的存储当中。
消费时判断数据是否可见:是指每次消费时判断是否有到期的延时消息,如果有则从第三方存储中拉取,供消费者消费。
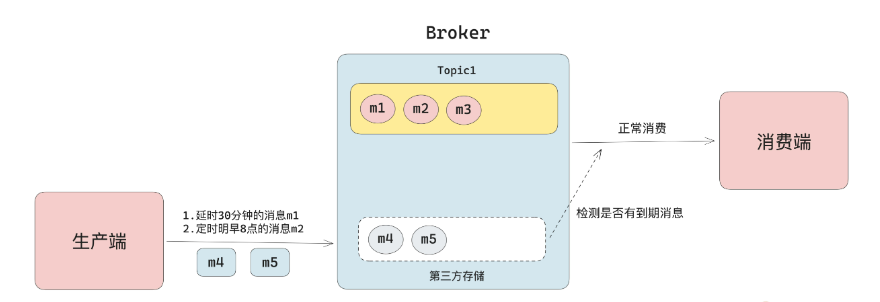
实际上,大多采用第一种方案。因为每次消费时都去判断一下是否有消息可见,则会对性能造成一定的影响。
定时机制的实现
定时机制的核心:随着时间的推移,拿出到期的延时消息进行处理。从技术上看,定时机制可以拆解为定时器和延时消息定位处理两部分。
定时器就是按照时间推进,说白了就是记录一下时间。
延时消息定位是指随着定时器的推进,在每个时间刻度可以高效定位,获取到该时刻需要处理的延时消息。
延时消息的技术方案
延时消息的实现主要有基于轮询检测机制的实现和基于时间轮机制的实现两种方案。
基于轮询检测机制的实现
核心思路:将消息写入到独立的存储当中,利用类似于while + sleep的定时器,来推进时间,通过独立线程检测数据是否到期,然后取出到期数据,存入正式存储。
我们可以将独立存储根据时间划分,大致结构如下:
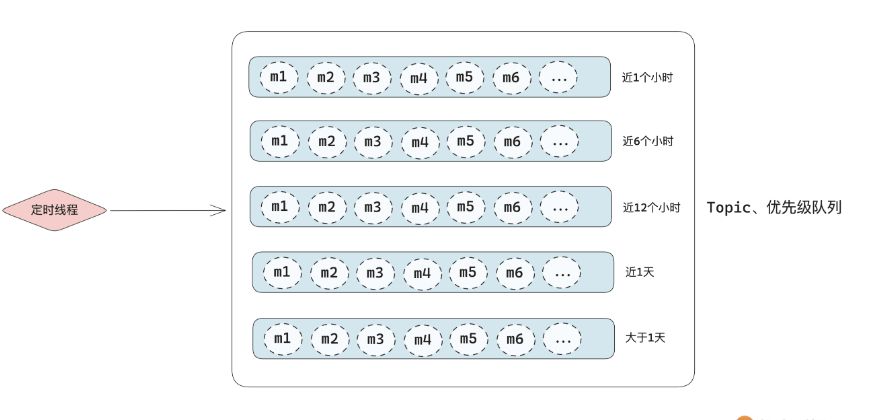
这样可以减小每个队列的长度。而每个队列采用什么结构,则可以根据实际的应用场景决定。
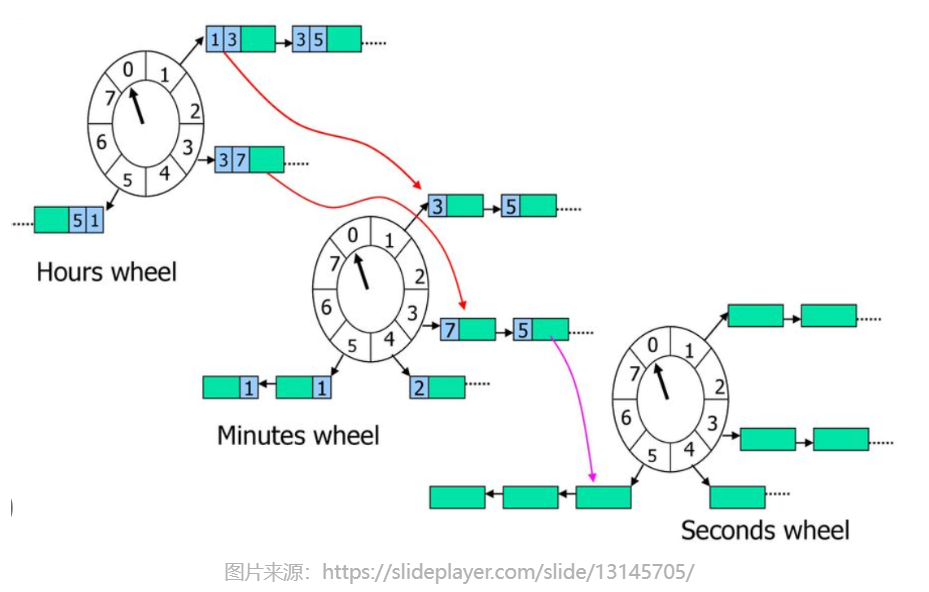
基于时间轮机制的实现
核心思路:将延时消息写入到独立的存储中,然后通过构建多级时间轮,在每个时间刻度上挂载需要处理的延时消息的索引列表。再依赖时间轮的推进,获取到需要处理的延时消息列表,进行后续的处理。
时间轮是一个很成熟的算法,分为单级时间轮和多级时间轮,具体结构如下:
参考
《深入拆解消息队列 47 讲》