
数据分区再平衡
分区再平衡
采用取余的坏处
如果采用取模的话,新添加节点或者删除节点,都有可能导致分区中的数据进行移动,最简单的例子,之前有10个节点,那么分区1000计算方法为1000%10 = 0,就在第0个分区,如果此时添加一个新的节点,变为了1000%11 = 10,此时就要将之前存在于下标为0的节点数据重新分配到下标为10的节点,导致性能损失。
固定分区数量
改策略是指提前规定好分区有多少个,比如说提前固定分区有1000个,然后当前有10个节点,那么每个节点就存在100个分区。这样做的好处就在于,如果存在新添加的节点,那么只需要将之前节点中存在的分区划分给新节点即可,如下图所示:
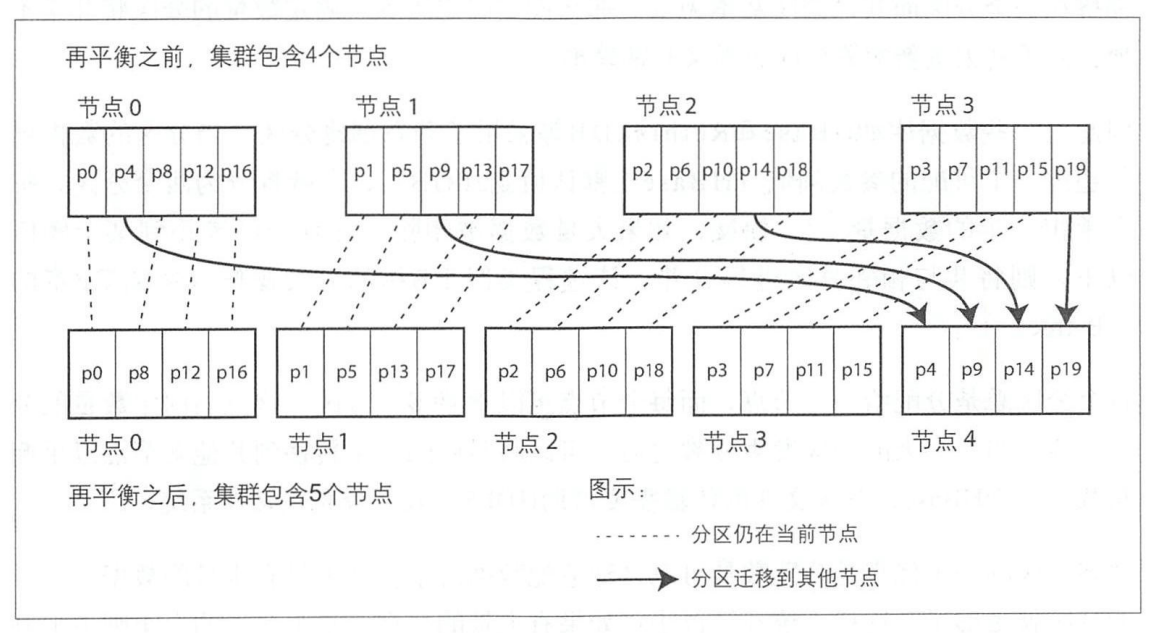
这样可以避免采用取余的坏处,并不需要频繁的移动每个分区的数据。
动态分区
如果之前的分区不是很合理,导致了一个分区中存在大量的数据,而其他分区几乎是空的,就可以利用到动态分区。
他的设计方式如下:提前设置一个阈值,当某一个分区达到该值之后,就会将该分区拆分为两个分区,如果某些分区数据特别少,那么就会将相邻的两个分区进行合并。该过程类似于B树的分裂或者合并。
它的一个优点是分区数量可以自适应数据的总量,但是在一个空数据库中,一开始可能只有一个分区,当道达分裂点后,后续的写入可能还是会在一个分区中进行。
按节点比例分区
该分区方式中,每个节点有固定数量的分区。
当节点数量不变时,每个分区的大小与数据集的大小成正比,当节点数增加时,分区则会调整变得更小。
当一个新的节点加入分区时,随机选择固定数量的分区进行分裂,然后拿走这些分区一半的数据量。
路由发现
当数据被分散到多个节点上时,我们读取数据的时候,如何知道我们想要的数据在哪里,这始终是一个问题,该问题也称为服务发现。
解决办法有以下三种:
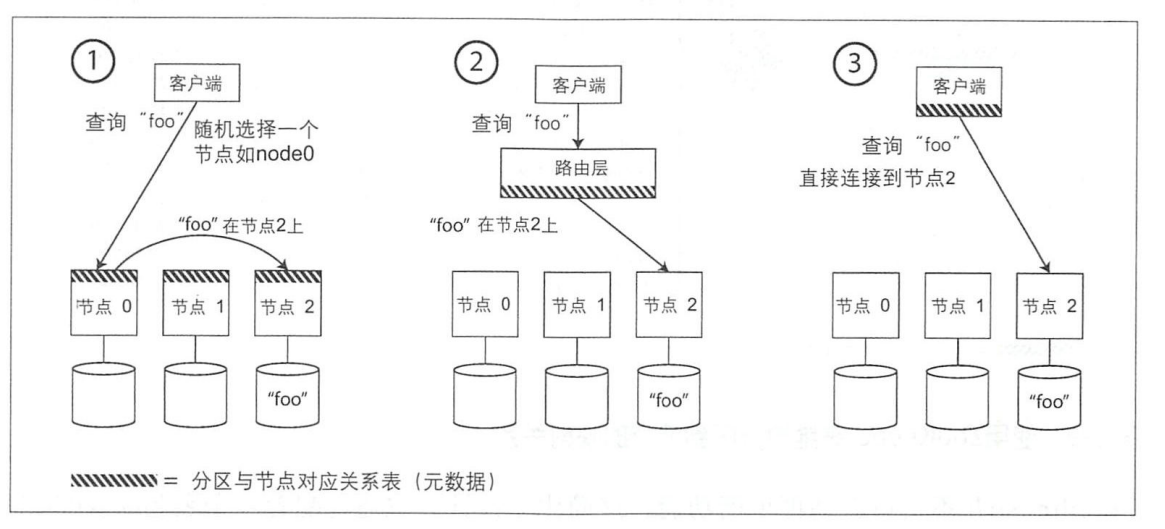
而该过程中,可能需要一些其他的第三方软件,比如Zookeeper。
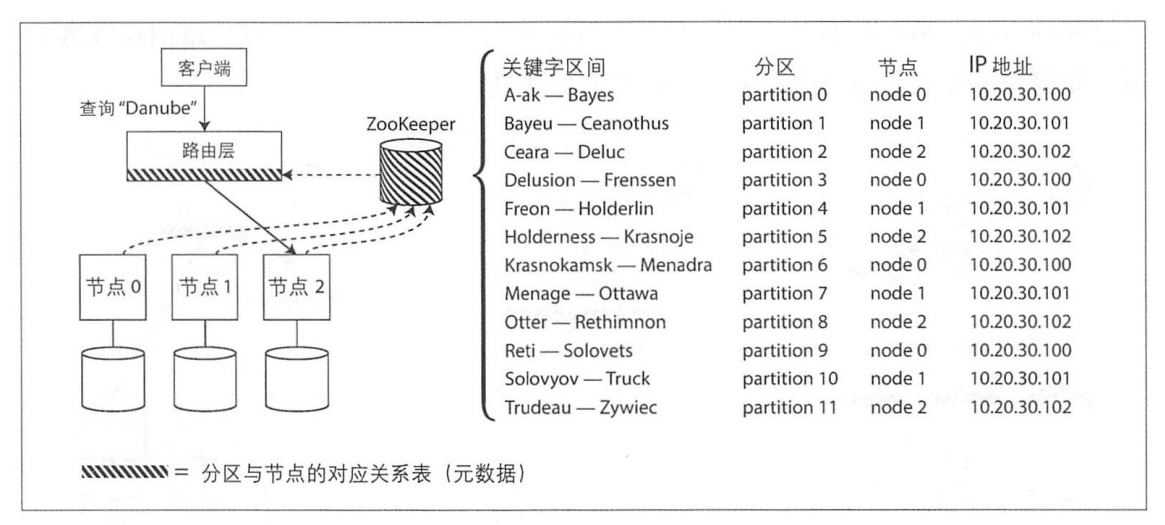
参考
《数据密集型系统设计》