
索引下推
索引下推
首先,MySQL的结构图如下:
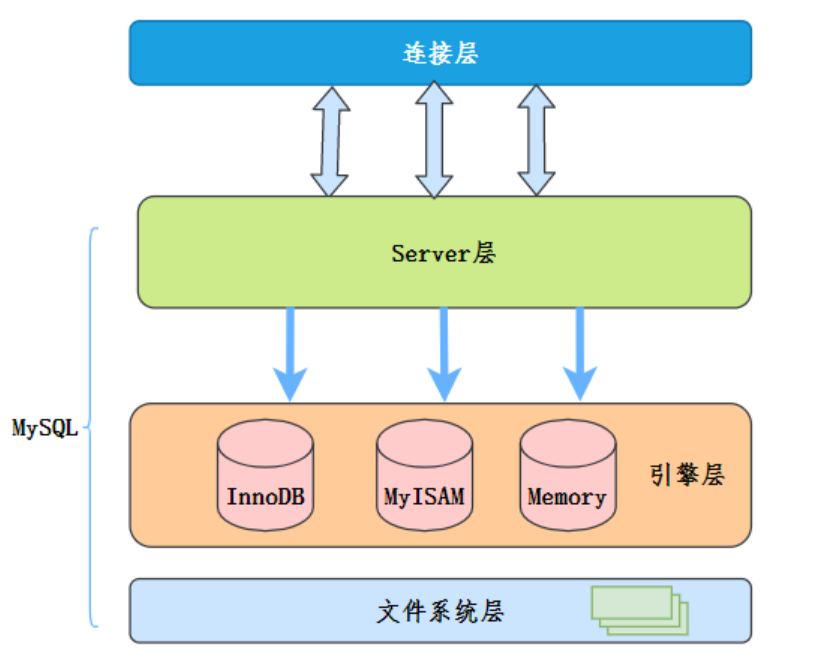
其中,Server层所做的事情,就是负责SQL的语法解析,生成执行计划,并调用存储引擎层去执行数据的存储核检索,判断引擎返回的数据是否满足where条件。索引下推就是指将上层(Server层)负责的事情,交给了下层(引擎层)去处理。具体的查询区别如下:
在没有使用索引下推时:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
而使用了索引下推的查询过程:
- 存储引擎读取索引记录(不是完整的行记录);
- 判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; - 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
这里的优化点在于,可以提前根据索引中的数据过滤掉一部分不满足的值,这一部分数据不需要回表查询,也不需要交由Server层去处理。
但是要注意,这个提前判断只能判断索引中存在的值,比如说where条件中有a , b , c 三个字段,但是这个索引(只能是二级索引,也叫辅助索引)是建立在a 和 b上面的,那么就只能提前判断a 和 b 是否满足,去除这两个不满足的,然后回表查询数据,返回给Server 然后去判断 c 是否满足条件。