
服务熔断
熔断
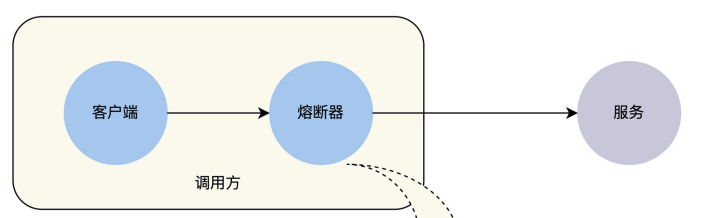
熔断机制:当服务之间发起调用的时候,如果被调用方返回的 指定错误码的比例超过一定的阈值,那么后续的请求将不会真正发起,而是由调用方直接返回错误。
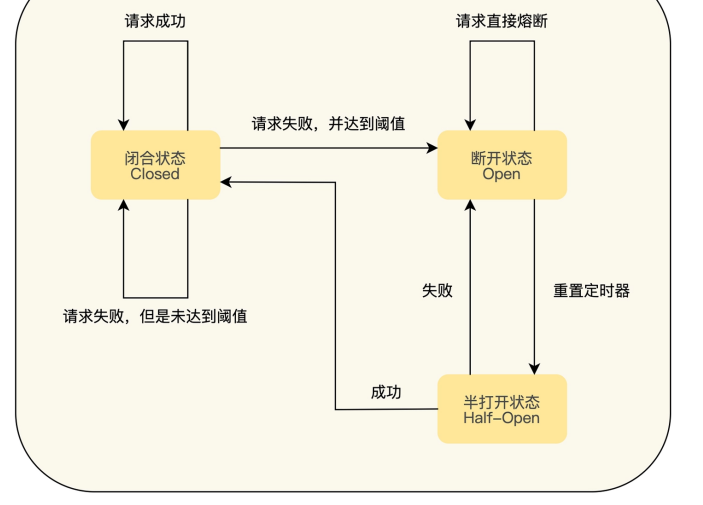
首先是闭合状态,此时可以处理请求,但是需要一个计数器,来统计调用失败的次数,如果失败的次数达到阈值,则将状态改为闭合。
在闭合状态下,可以直接拒绝后续的请求,也可以对请求做一个降级(后续介绍)。此时会启动一个超时计时器,当计时器超时后,会转变为半打开状态。
在半打开状态下,允许一定数量的请求发往被调用的服务,如果这些调用正常,则就可以认为被调用服务已经恢复正常,此时熔断器切换为闭合状态,同时重置计数器。如果仍有部分调用失败的情况,则认为被调用方仍然没有恢复,熔断器会切换到断开状态,然后重置计数器。半打开状态是为了防止恢复中的服务被大量请求再次打垮的情况。
熔断的关键点
有以下五个关键点:粒度控制、错误类型、存活与过载的区别、重试和熔断的关系和熔断机制的适应范围。
粒度控制
该问题是指我们想将监控资源过载的粒度控制在一个什么样的范围内,这个范围可以由服务、实例和接口这三个维度的组合来得到。
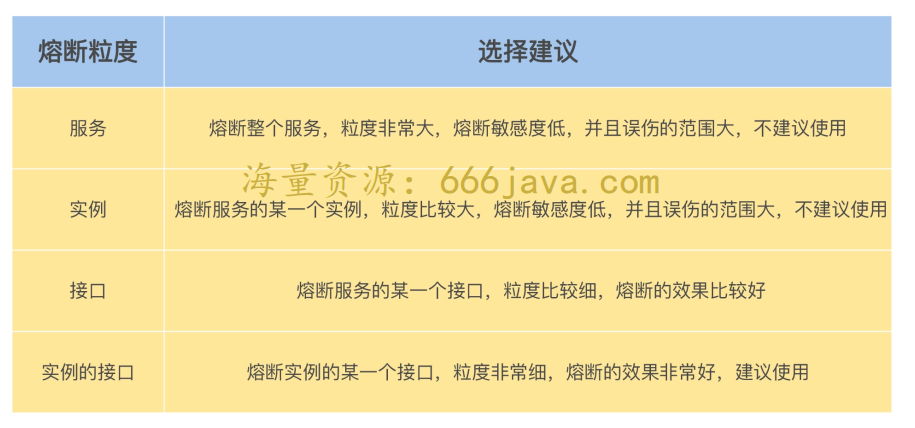
建议使用基于实例接口的熔断,这样的粒度最小,假如说一个实例有10个接口,只有一个接口请求超时,那么熔断该接口即可,其他接口仍然可以提供服务,将熔断的错误率讲到最低。
错误类型
由于熔断机制是用来消除系统过载的,所以,我们需要识别出与系统过载相关的错误,来进行 熔断处理,一般来说,主要有下面两个错误类型。
- 系统被动对外表现出来的过载错误,一般来说,如果一个接口过载了,那么它的响应时间就会变长,熔断器捕获到的错误类型就是“响应超时”之类的超时错误。
- 系统主动对外表现出来的过载错误,对于这种情况,一般是请求的流量触发了限流等机制返回的错误码,这个是我们在程序开发过程中主动设计的。
过载与存活的区别
熔断机制关心系统是否过载,最好的判断方式为利用队列中的平均等待时间来计算服务的负载。不利用服务的处理时间是为了考虑下游任务的处理时间,有时可能是因为下游处理太慢而导致的当前服务处理时间较长。
在熔断场景中,我们对过载判断进行了简化,直接通过接口请求的结果进行判断,如果发生请求错误,并且错误为超时或者限流等错误的比例超过一定的阈值,我们就可以认为系统过载,然后进行熔断。
而存活一般是指机器或者服务是否存活,对于机器是否存活,一般是通过定期 ping 机器的 IP ,如果超过一定时间不能 ping 通,则认为该机器不存活了。
熔断与重试的关系
熔断和重试都会对服务之间的调用请求进行额外的处理,不同的是,重试是指我们认为该次调用失败是因为系统临时错误导致的,所以重发一次请求。而熔断是指我们已经认为系统过载了,为了保证系统不发生雪崩,为了使接口快速处理,而直接返回失败。
熔断机制的适应范围
只要是过载问题的场景, 我们都可以考虑利用熔断机制来解决,不论是分布式系统中服务之间的调用,还是服务与数据 库之间等其他场景的调用
参考
《深入浅出分布式技术原理》