
RabbitMQ的设计
下图是RabbitMQ的系统架构:
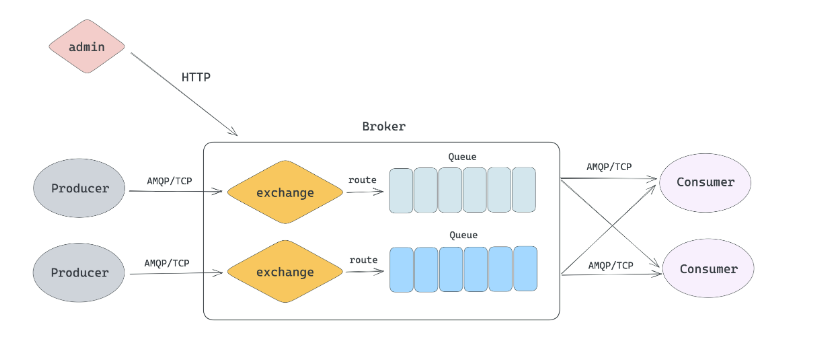
RabbitMQ 由 Producer、Broker、Consumer 三个大模块组成。
生产者将数据发送到 Broker,Broker 接收到数据后,将数据存储到对应的 Queue 里面,消费者从不同的 Queue 消费数据。它有 Exchange、Bind、Route 这几个独有的概念。
Exchange 称为交换器,它是一个逻辑上的概念,用来做分发,本身不存储数据。流程上生产者先将消息发送到 Exchange,而不是发送到数据的实际存储单元 Queue 里面。然后 Exchange 会根据一定的规则将数据分发到实际的 Queue 里面存储。
这个分发过程就是 Route(路由),设置路由规则的过程就是 Bind(绑定)。即 Exchange 会接收客户端发送过来的 route_key,然后根据不同的路由规则,将数据发送到不同的 Queue 里面。
协议和网络模块
在网络通信协议层面,RabbitMQ 数据流是基于四层 TCP 协议通信的,跑在 TCP 上的应用层协议是 AMQP。
RabbitMQ 的网络层有 Connectoion 和 Channel 两个概念需要注意。
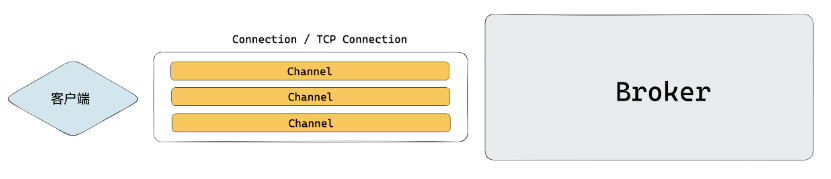
Connection 是指 TCP 连接,Channel 是 Connection 中的虚拟连接。两者的关系是:一个客户端和一个 Broker 之间只会建立一条 TCP 连接,就是指 Connection。Channel(虚拟连接)的概念在这个连接中定义,一个 Connection 中可以创建多个 Channel。
客户端和服务端的实际通信都是在 Channel 维度通信的。
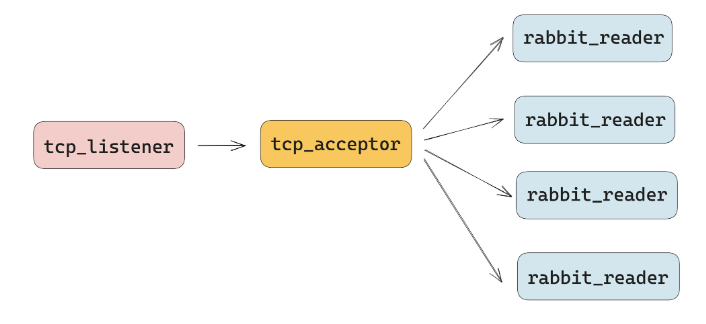
RabbitMQ 服务端通过 tcp_listener 监听端口,tcp_acceptor 接收请求,rabbit_reader 处理和返回请求。本质上来看是也是一个多线程的网络模型。
数据存储
RabbitMQ 的存储模块也包含元数据存储与消息数据存储两部分。RabbitMQ 的两类数据都是存储在 Broker 节点上的。
元数据存储
RabbitMQ 的元数据都是存在于 Erlang 自带的分布式数据库 Mnesia 中的。即每台 Broker 都会起一个 Mnesia 进程,用来保存一份完整的元数据信息。Mnesia是一个分布式数据库,自带了多节点自动同步机制。
消息数据存储
RabbitMQ 消息数据的最小存储单元是 Queue,即消息数据是按顺序写入存储到 Queue 里面的。
在底层的数据存储方面,所有的 Queue 数据是存储在同一个“文件”里面的。这个“文件”是一个虚拟的概念,表示所有的 Queue 数据是存储在一起的意思。
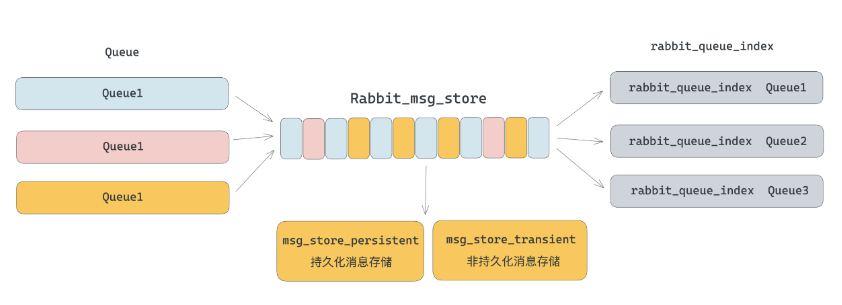
这个“文件”由队列索引(rabbit_queue_index)和消息存储(rabbitmq_msg_store)两部分组成。即在节点维度,所有 Queue 数据都是存储在 rabbit_msg_store 里面的,每个节点上只有一个 rabbit_msg_store,数据会依次顺序写入到 rabbit_msg_store 中。
rabbit_msg_store 是一个逻辑概念,底层的实际存储单元分为两个,msg_store_persistent 和 msg_store_transient,分别负责持久化消息和非持久化消息的存储。
这里所有的消息都会以追加的形式写入一个文件当中,当一个文件的大小超过了配置的最大大小,就会新开一个文件来存储。
队列索引负责存储、维护队列中落盘消息的信息,包括消息的存储位置、是否交付、是否 ACK 等等信息。队列索引是 Queue 维度的,每个 Queue 都有一个对应的队列索引。
删除消息时,不会立即删除数据,只是从 Erlang 中的 ETS 表删除指定消息的相关信息,同时更新消息对应的存储文件的相关信息。此时文件中的消息不会立即被删除,会被标记为已删除数据,直到一个文件中都是可以删除的数据时,再将这个文件删除,这个动作就是常说的延时删除。另外内核有检测机制,会检查前后两个文件中的数据是否可以合并,当符合合并规则时,会进行段文件的合并。
生产者和消费者
当生产者和消费者连接到 Broker 进行生产消费的时候,是直接和 Broker 交互的,不需要客户端寻址。
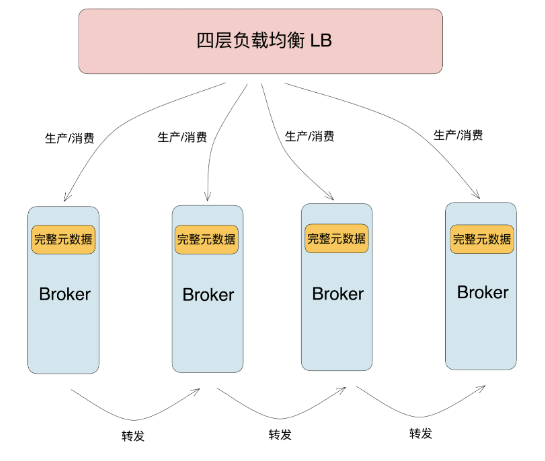
RabbitMQ 集群部署后,为了提高容灾能力,就需要在集群前面挂一层负载均衡来进行灾备。但是一个客户端拿到负载均衡ip的时候,去对应的Broker去消费数据,可能会出现该条消息并不存储于该Broker而导致消费失败。
为了解决这个问题,每个 Broker 上会设置有转发的功能。在实现上,每台 Broker 节点都会保存集群所有的元数据信息。当 Broker 收到请求后,根据本地缓存的元数据信息判断 Queue 是否在本机上,如果不在本机,就会将请求转发到 Queue 所在的目标节点。
生产端发送数据不是直接发送到 Queue,而是直接发送到 Exchange。即发送时需要指定 Exchange 和 route_key,服务端会根据这两个信息,将消息数据分发到具体的 Queue。
在消费端,RabbitMQ 支持 Push(推)和 Pull(拉)两种模式,如果使用了 Push 模式,Broker 会不断地推送消息给消费者(如果有消息的情况下)。推送消息的个数会受到 channel.basicQos 的限制,不能无限推送,在消费端会设置一个缓冲区来缓冲这些消息。
拉模式是指客户端不断地去服务端拉取消息,RabbitMQ 的拉模式只支持拉取单条消息。
参考
《深入拆解消息队列 47 讲》