
消费客户端的SDK(下)
这里介绍上篇剩下的三部分,也就是消费分组(订阅)、消费确认、消费失败处理。
消费分组
消费分组是用来组织消费者、分区、消费进度关系的逻辑概念。
在没有消费分组直接消费 Topic 的场景下,如果希望不重复消费 Topic 中的数据,那么就需要有一个标识来标识当前的消费情况,比如记录进度。这个唯一标识就是消费分组。
消费分组主要有管理消费者和分区的对应关系、保存消费者的消费进度、实现消息可重复被消费三类功能。
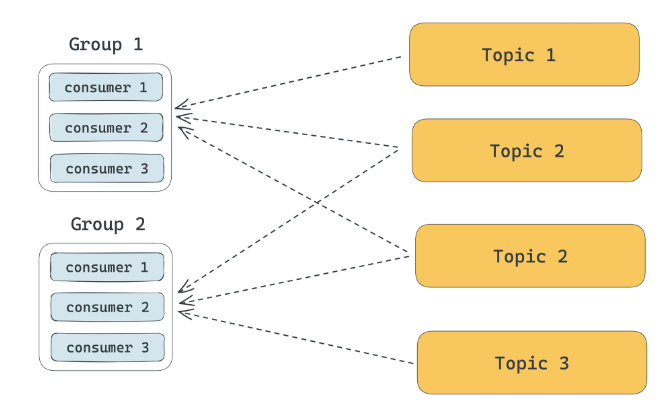
因为 Topic 不存储真实数据,分区才存储消息数据,所以就需要解决消费者和分区的分配关系,即哪个分区被哪个消费者消费,这个分配的过程就叫做消费重平衡(Rebalance)。
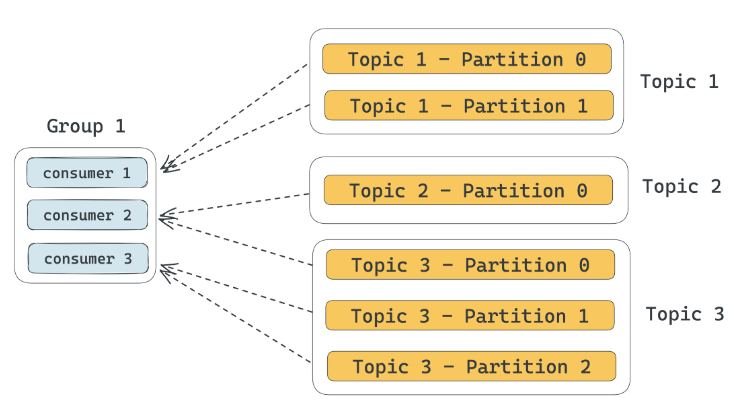
由上图可以看出,当新增一个消费分组时,为了使得消费平衡,就需要重新分配消费关系。
协调者
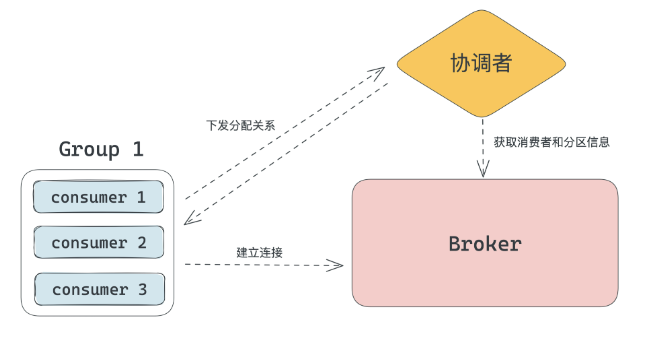
如果要对消费者和分区进行分配,肯定需要有一个模块拥有消费分组、所有的消费者、分区信息三部分信息,这个模块我们一般命名为协调者。协调者主要的工作就是执行消费重平衡,并记录消费分组的消费进度。
分区分配的操作可以在协调者内部或者消费者上完成。这两种,一种是协调者获得所有的信息,然后进行分配,分配完同步给其他的消费者。一种是一个消费者获取所有其他消费者和分区的信息,进行分配操作,之后同步给其他消费者。
消费分区分配策略
分区分配策略的制定一般遵循以下三个原则:
- 各个分区的数据能均匀地分配给每个消费者,保证所有消费者的负载最大概率是均衡的。
- 在每次重新分配的时候,尽量减少分区和消费者之间的关系变动,这样有助于加快重新分配的速度,并且保持数据处理的连续性,降低处理切换成本。
- 可以允许灵活地根据业务特性制定分配关系
所有消息队列的默认策略都是相对通用的,一般都会包含有轮询、粘性、自定义三种类型的策略。
轮询就是指用轮询的方式将分区分配给各个消费者,保证每个消费者的分区数量是尽量相同的,从而保证消费者的负载最大概率上是均衡的。但是这种方案可能导致几个流量较高的分区分给了同一个消费者,为了解决这个问题,在随机的基础上,将 Topic 的不同分区尽量打散到不同的消费者,从而保证整体消费者之间的分区是均衡的(即同一个topic下的不同partition分给不同的消费者)。
粘性是指尽量减少分区分配关系的变动,进而减少重平衡所耗费的时间和资源损耗。即当有新的分区加入,或者老的分区挂掉,在重新分配时,应尽可能减少变动。
自定义就是提供接口,用户自己实现。
消费确认
当消息被消费时,就必须进行消费确认,即告诉服务端这条消息已经被消费了,也就是常说的ACK。
一般情况下,消息确认分为确认后删除数据和确认后保存消费进度数据两种形式。
确认后删除数据是指集群的每条消息只能被消费一次,只要数据被消费成功,就会回调服务端的 ACK 接口,服务端就会执行数据删除操作。这种方案不利于回溯,所以用的不多。
消费成功保存消费进度是指当消费数据成功后,调用服务端的消费进度接口来保存消费进度。这种方式一般都是配合消费分组一起用的,服务端从消费分组维度来保存进度数据。

为了保证消息的回溯和多次消费,一般都采用这种方案。数据的删除交由数据过期策略去执行。
保存消费进度一般分为服务端保存和客户端自定义保存两种实现机制。
服务端保存是指服务端提供一个接口用于保存数据,客户端调用即可。服务端一般会通过内置的 Topic 或者文件来持久保存该数据。
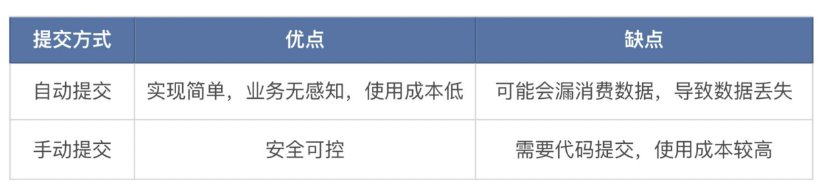
在提交位点信息的时候,底层一般支持自动提交和手动提交两种实现。
- 自动提交一般是根据时间批次或数据消费到客户端后就自动提交,提交过程客户无感知。
- 手动提交是指业务根据自己的处理情况,手动提交进度信息,以避免业务处理异常导致的数据丢失。
优缺点如下:
客户端自定义保存是指当消费完成后,客户端自己管理保存消费进度。
消费失败处理
一个完整的消费流程包括消费数据、本地业务处理、消费进度提交三部分,那么从消费失败的角度来看,就应该分为从服务端拉取数据失败、本地业务数据处理失败、提交位点信息失败三种情况。
从服务端拉取数据失败,和客户端的错误逻辑处理是一致的,根据可重试错误和不可重试错误的分类,进行重复消费或者向上抛错。
本地业务数据处理失败,如果是偶尔失败,那么在业务层做好重试处理逻辑,配合手动提交消费进度的操作即可解决。如果是一直失败,即使重试多次也无法被解决,此时如果一直重试,就会出现消费卡住的情况,这就需要配合死信队列的功能,将无法被处理的数据投递到死信队列中,从而保存异常数据并保证消费进度不阻塞。
提交位点信息失败,其处理方法通常是一直重试,重复提交,如果持续失败就向上抛错。因为如果提交进度失败,即使再从服务端拉取数据,还是会拉到同一批数据,出现重复消费的问题。
参考
《深入拆解消息队列 47 讲》