
消费客户端的SDK(上)
从实现来看,消费相关功能包括消费模型、分区消费模式、消费分组(订阅)、消费确认、消费失败处理五个部分。
这里只涉及到前两个部分。
消费模型的选择
为了满足不同场景的业务需求,从实现机制上来看,主流消息队列一般支持 Pull、Push、Pop 三种消费模型。
Pull 模型
Pull(拉)模型是指客户端通过不断轮询的方式向服务端拉取数据。它是消息队列中使用最广泛和最基本的模型,主流的消息队列都支持这个模型。
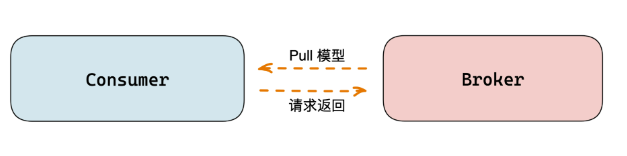
它的好处是客户端根据自身的处理速度去拉取数据,不会对客户端和服务端造成额外的风险和负载压力。缺点是可能会出现大量无效返回的 Pull 调用(服务端没有数据可以拉去时),另外消费及时性不够。
为了提高性能,Pull是可以指定一次拉去多少条数据,然后传递给服务端,即批量拉取。
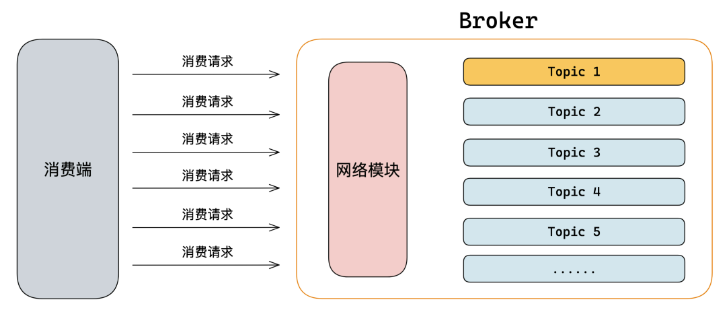
如上图,如果Topic1的数据已经被消费完,但是客户端还是不断的发请求拉数据,那么就会导致资源的浪费。
为了解决这个问题,一般服务端会协助处理,有如下两个思路:
1. 服务端 hold 住请求
当客户端根据策略拉取数据时,如果没有足够的数据,就先在服务端等一段时间,等有数据后一起返回给客户端。
好处是可以尽可能提高吞吐率,而且不会有太多的空请求。
缺点是如果长时间没有消息,则会导致消费者请求超时,而且如果数据长时间不够,则会提高消费时延。
2. 服务端有数据的时候通知客户端
当服务端不 hold 住请求,立刻返回空数据,客户端收到空数据时则不再发起请求,会等待服务端的通知。当服务端有数据的时候,再主动通知客户端来拉取。
这种方案的好处是可以及时通知客户端来拉取数据,从而降低消费延时。
缺点是因为客户端和服务端一般是半双工的通信,此时服务端是不能主动向客户端发送消息的。
所以在 Pull 模型中,比较合适的方案是客户端告诉服务端:最多需要多少数据、最少需要多少数据、未达到最小数据时可以等多久三个信息。然后服务端首先判断是否有足够的数据,有的话就立即返回,否则就根据客户端设置的等待时长 hold 住请求,如果超时,无论是否有数据,都会直接给客户端返回当前的结果。
Push 模型
Push(推)模型是为了解决消费及时性而提出来的。这个模型的本意是指当服务端有数据时会主动推给客户端,让数据的消费更加及时。
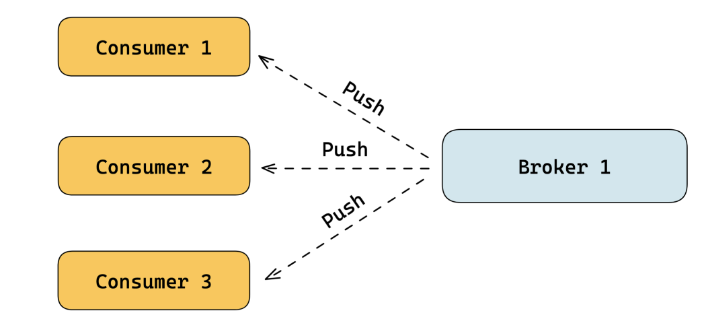
在实际的 Push 模型的实现上,一般有 Broker 内置 Push 功能、Broker 外独立实现 Push 功能的组件、在客户端实现伪 Push 功能三种思路。
第一种,Broker内置Push功能是指在 Broker 中内置标准的 Push的能力,由服务端向客户端主动推送数据。
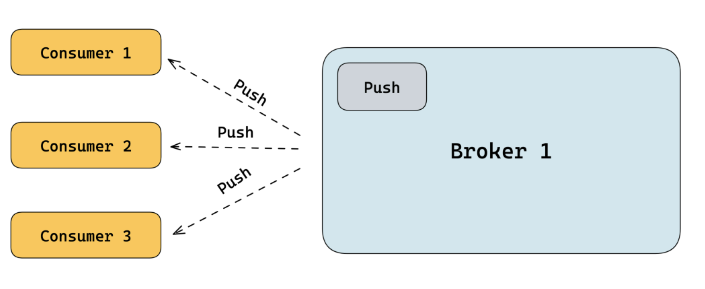
优点:Broker 自带 Push 能力,无需重复开发和部署。Broker 内部可以感知到数据堆积情况,可以保证消息被及时消费。
缺点:当消费者很多时,内核需要主动维护很多与第三方的长连接,并且需要处理各种客户端异常,推送数据,异常处理等比较耗费系统资源,可能会导致Broker不稳定。
第二种,Broker 外独立实现 Push 功能的组件是指独立于 Broker 提供一个专门实现推模型的组件。
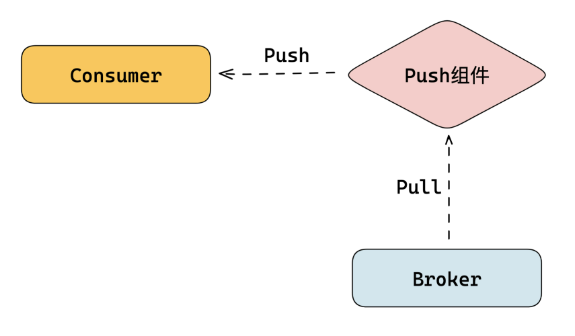
好处是将push组件独立了出来,可以保证Broker的稳定。
缺点是需要先pull拉去数据,然后再push,会存在较高的时延。
第三种,在客户端实现伪 Push 功能是指在客户端内部维护内存队列,SDK 底层通过 Pull 模型从服务端拉取数据存储到客户端的内存队列中。然后通过回调的方式,触发用户设置的回调函数,将数据推送给应用程序,在使用体验上看就是 Push 的效果。
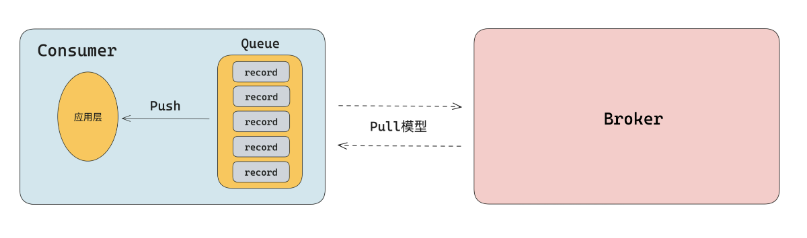
这种方案的好处在于通过客户端底层的封装,从用户体验看是 Push 模型的效果,解决用户代码层面的不断轮询问题。
缺点是底层依旧是 Pull 模型,还是得通过不断轮询的方式去服务端拉取数据,就会遇到 Pull 模型遇到的问题。
因为 Push 模型需要先分配分区和消费者的关系,客户端就需要感知分区分配、分区均衡等操作,从而在客户端就需要实现比较重的逻辑。并且当客户端和订阅的分区数较多时,容易出现需要很长的重平衡时间的情况。此时为了解决这个问题,业界提出了 Pop 模型。
Pop 模型
Pop 模型想解决的是客户端实现较重,重平衡会暂停消费并且可能时间较长,从而出现消费倾斜的问题。
它的思路是客户端不需要感知到分区,直接通过 Pop 模型提供的 get 接口去获取到数据,消费成功后 ACK 数据。就跟我们发起 HTTP 请求去服务端拉取数据一样,不感知服务端的数据分布情况,只需要拉到数据。
这种方案的好处是简化了消费模型,同时服务端可以感知到消费的堆积情况,可以根据堆积情况返回那些分区的数据给客户端,这样也简化了消息数据的分配策略。
从实现上来看,它将分区分配的工作移到了服务端,在服务端完成了消费者的分区分配、进度管理,然后暴露出了新的 Pop 和 ACK 接口。客户端调用 Pop 接口去拿取数据,消费成功后调用 ACK 去确认数据。

分区消费模式的设计
消息队列的数据是在 Partition/Queue 维度承载的。所以消费过程中一个重要的工作就是消费者和分区的消费模式问题,即分区的数据能不能被多个消费者并发消费,一条数据能不能被所有消费者消费到,分区的数据能不能被顺序消费等等。
从技术上看,在数据的消费模式上主要有独占消费、共享消费、广播消费、灾备消费四个思路。
独占消费
独占消费是指一个分区在同一个时间只能被一个消费者消费。在消费者启动时,会分配消费者和分区之间的消费关系。当消费者数量和分区数量都没有变化的情况下,两者之间的分配关系不会变动。
如果消费者数量大于分区数量,则会有消费者被空置;
反之,如果分区数量大于消费者数量,一个消费者则可以同时消费多个分区。
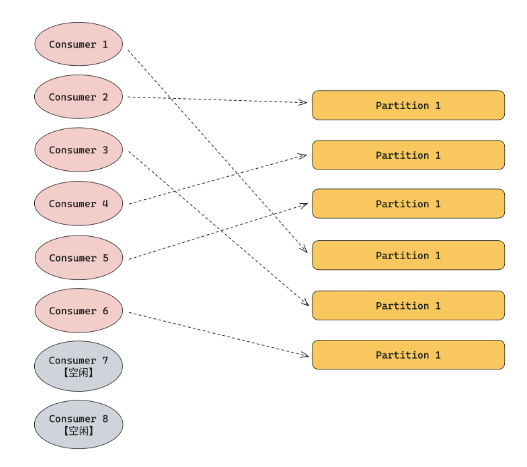
独占消费的好处是可以保证分区维度的消费是有序的。缺点是当数据出现倾斜、单个消费者出现性能问题或 hang 住时,会导致有些分区堆积严重。
共享消费
共享消费是指单个分区的数据可以同时被多个消费者消费。即分区的数据会依次投递给不同的消费者,一条数据只会投递给一个消费者。
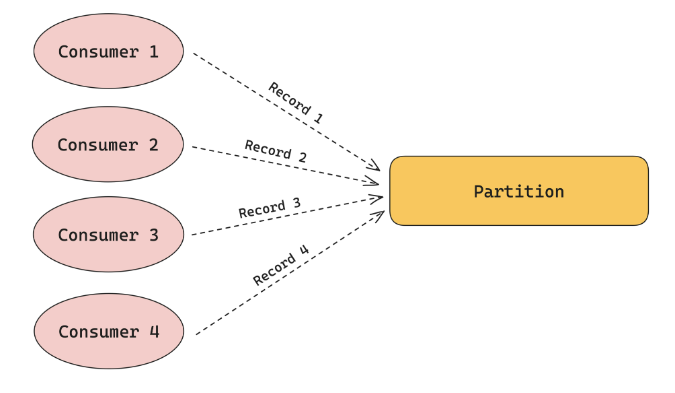
这种方式的好处是,可以避免单个消费者的性能和稳定性问题导致分区的数据堆积。缺点是无法保证数据的顺序消费。这种模式一般用在对数据的有序性无要求的场景,比如日志。
广播消费
广播消费是指一条数据要能够被多个消费者消费到。即分区中的一条数据可以投递给所有的消费者,这种方式是需要广播消费的场景。
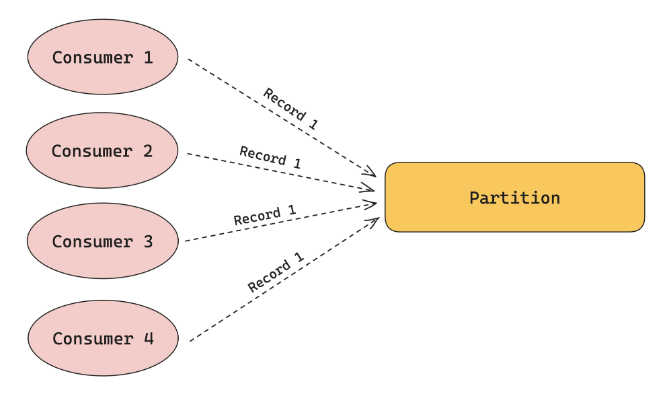
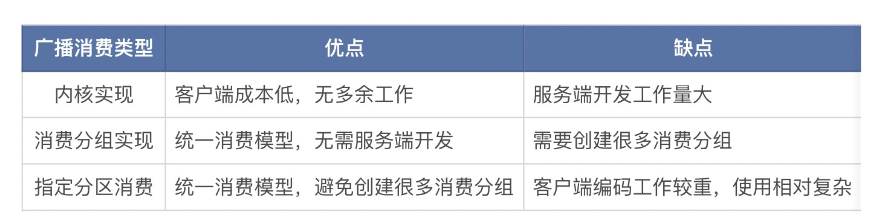
实现广播消费一般有内核实现广播消费的模型、使用不同的消费分组消费和指定分区消费三种技术思路。
- 内核实现广播消费的模型,指在 Broker 内核中的消息投递流程实现广播消费模式,即 Broker 投递消息时,可以将一条消息吐给不同的消费者,从而实现广播消费。
- 使用不同的消费分组对数据进行消费,指通过创建不同的消费者组消费同一个 Topic 或分区,不同的消费分组管理自己的消费进度,消费到同一条消息,从而实现广播消费的效果。
- 指定分区消费,是指每个消费者指定分区进行消费,在本地记录消费位点,从而实现不同消费者消费同一条数据,达到广播消费的效果。
优缺点如下:
灾备消费
灾备消费是独占消费的升级版,在保持独占消费可以支持顺序消费的基础上,同时加入灾备的消费者****。当消费者出现问题的时候,灾备消费者加入工作,继续保持独占顺序消费。
好处是既能保持独占顺序消费,又能保证容灾能力。缺点是无法解决消费倾斜的性能问题,另外还需要准备一个消费者来做灾备,使用成本较高。
参考
《深入拆解消息队列 47 讲》