
生产者的SDK需要哪些设计
生产模块包含客户端基础功能和生产相关功能两部分,如下图:
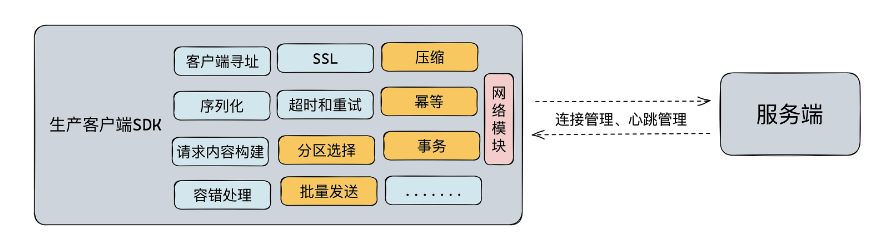
基础功能是蓝色部分,生产功能是黄色部分。
客户端基础功能
连接管理
客户端和服务端之间基本都是创建 TCP 长连接进行通信的,为了避免连接数膨胀,每个客户端实例和每台 Broker 只会维护一条 TCP 连接。
分为两种:
- 初始化创建连接,指在实例初始化时就创建到各个 Broker 的 TCP 连接,等待数据发送。这种可能会导致连接空跑,会消耗一定的资源。
- 使用时创建链接,指在实例初始化时不建立连接,当需要发送数据时再建立。可能出现连接冷启动,会增加一点本次请求的耗时。
心跳检测
消息队列一般都是基于 TCP 协议通信的,所以客户端和服务端之间的心跳检测机制的实现,一般有基于 TCP 的 KeepAlive 保活机制和应用层主动探测两种形式。
基于 TCP 的 KeepAlive 保活机制是 TCP/IP 协议层内置的功能,需要手动打开,优点是简单,缺点是需要Server主动发出检测包,当客户端出现故障而Server没有发包时,可能会出现不可用的TCP连接占用服务器资源。
应用层主动探测一般是 Client 向 Server 发起的,探测流程一般是客户端定时发送保活心跳,当服务端连续几次没收到请求,就断开连接。可以降低服务端压力。
错误处理
从请求的角度,有些错误是重试可以恢复的,比如连接断开、Leader 切换、发送偶尔超时、服务端某些异常等;有些错误是不可恢复的,比如 Topic/ 分区不存在、服务端 Broker 不存在、集群和 Broker 长时间无响应等。
所以,在客户端的处理中也会将错误分为可重试错误和不可重试错误两类。
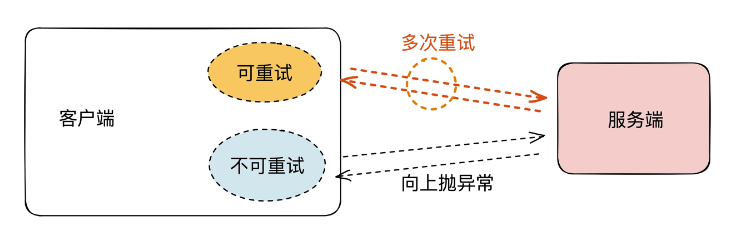
可重试指的是那些因为网络波动,Leader切换等异常,重试之后有可能解决的错误,不可重试的错误就是不管如何重试都无法恢复的异常。
重试机制
重试策略一般会支持重试次数和退避时间的概念。当消息失败,超过设置的退避时间后,会继续重试,当超过重试次数后,就会抛弃消息或者将消息投递到配置好的重试队列中。
退避策略影响的是重试的成功率,因为网络抖动正常是 ms 级,某些异常可能会抖动十几秒。此时,如果退避策略设置得太短,在退避策略和重试次数用完后,可能消息还没生产成功;如果退避时间设置太长,可能导致客户端发送堵塞消息堆积。
生产相关功能
客户端寻址机制
消息队列作为一个分布式系统,分区会分布在集群的不同节点上。那么客户端给服务端发送数据时,要发给哪台节点呢?
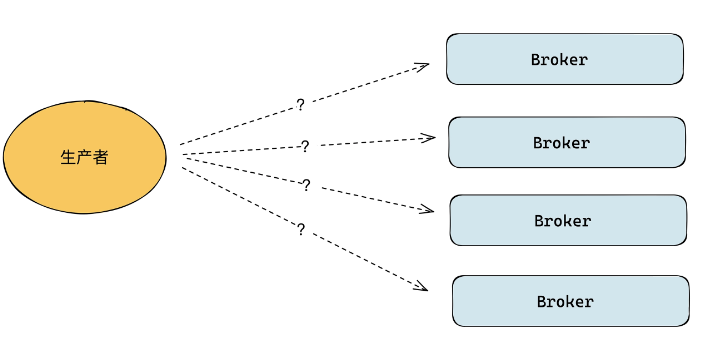
一种思路是:手动指定目标 Broker 的 IP,就是说在生产者写数据到 Broker 的时候,在代码里面手动指定分区对应的对端的 Broker 地址,然后将数据写到目标 Broker。
为了解决查找分区在Broker上的对应关系,业界提出了 Metadata(元数据)寻址机制和服务端内部转发两个思路。
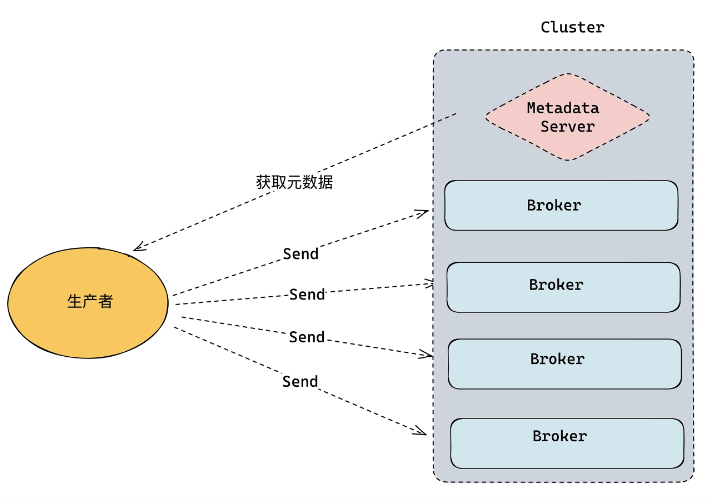
1. Metadata(元数据)寻址机制
服务端会提供一个获取全量的 Metadata 的接口,客户端在启动时,首先通过接口拿到集群所有的元数据信息,本地缓存这部分数据信息。然后,客户端发送数据的时候,会根据元数据信息的内容,得到服务端的地址是什么,要发送的分区在哪台节点上。最后根据这两部分信息,将数据发送到服务端。
简而言之,通过接口查到对应的数据,下次请求时带上就可以了。
消息队列的元数据是指 Topic、分区、Group、节点、配置等集群维度的信息。比如 Topic 有几个分区,分区的 Leader 和 Follower 在哪些节点上,节点的 IP 和端口是什么,有哪些 Group 等等。
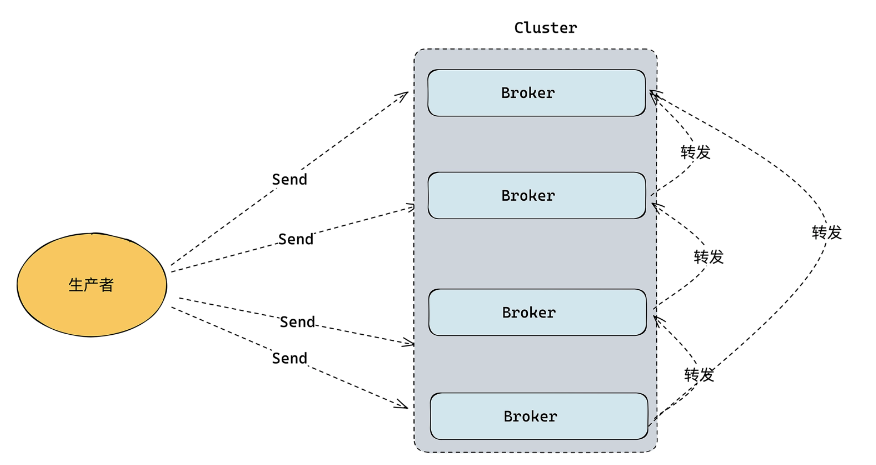
2. 服务端内部转发机制
另外一种服务端内部转发机制,客户端不需要经过寻址的过程,写入的时候是随机把数据写入到服务端任意一台 Broker。
具体思路是服务端的每一台 Broker 会缓存所有节点的元数据信息,生产者将数据发送给 Broker 后,Broker 如果判断分区不在当前节点上,会找到这个分区在哪个节点上,然后把数据转发到目标节点。
简单来说就是随便发到任意一个Broker中,然后他们之间有类似路由信息,Broker之间再进行转发。
生产分区分配策略
数据可以直接写入分区或者写入 Topic。写入 Topic 时,最终数据还是要写入到某个分区。这个数据选择写入到哪个分区的过程,就是生产数据的分区分配过程。过程中的分配策略就是生产分区分配策略。
一般情况下,消息队列默认支持轮询、按 Key Hash、手动指定、自定义分区分配策略四种分区分配策略。
轮询
轮询是所有消息队列的默认选项。消息通过轮询的方式依次写入到各个分区中,这样可以保证每个分区的数据量是一样的,不会出现分区数据倾斜。
但是如果我们需要保证数据的写入是有序的,轮询就满足不了。因为在消费模型中,每个分区的消费是独立的,如果数据顺序依次写入多个分区,在消费的时候就无法保持顺序。所以为了保证数据有序,就需要保证 Topic 只有一个分区。这是另外两种分配策略的思路。
按 Key Hash
按 Key Hash 是指根据消息的 Key 算出一个 Hash 值,然后跟 Topic 的分区数取余数,算出一个分区号,将数据写入到这个分区中。
这种方案的好处是可以根据 Key 来保证数据的分区有序。比如某个用户的访问轨迹,以客户的 AppID 为 Key,按 Key Hash 存储,就可以确保客户维度的数据分区有序。(因为key是一样的,所以该用户的所有消息会被分到一个分区当中)
缺点是分区数量不能变化,变化后 Hash 值就会变,导致消息乱序。并且因为每个 Key 的数据量不一样,容易导致数据倾斜。
手动指定
在生产数据的时候,手动指定数据写入哪个分区。
自定义分区分配策略
用户实现消息队列提供的接口,自定义分区策略。
批量语义
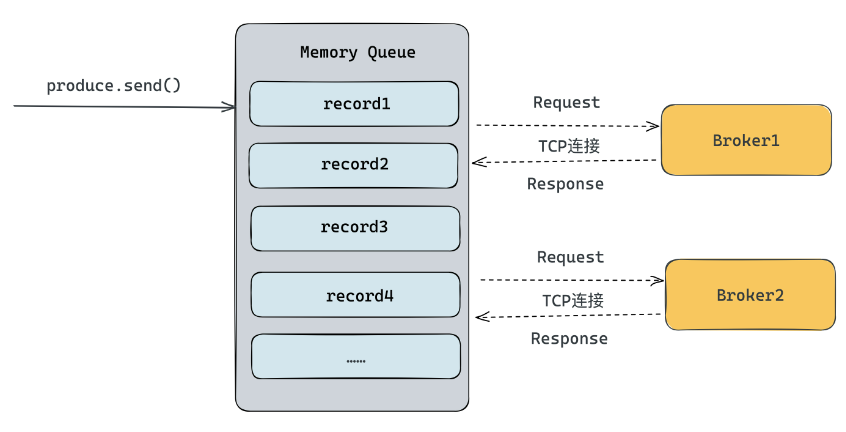
客户端支持批量写入数据的前提是,需要在协议层支持批量的语义。否则就只能在业务中自定义将多条消息组成一条消息。
批量发送的实现思路一般是在客户端内存中维护一个队列,数据写入的时候,先将其写到这个内存队列,然后通过某个策略从内存队列读取数据,发送到服务端。
数据发送方式
消息队列一般也会提供同步发送、异步发送、发送即忘三种形式。
同步异步好理解,不再过多阐述。
发送即忘指消息发送后不关心请求返回的结果,立即发送下一条。这种方式因为不用关心发送结果,发送性能会提升很多。缺点是当数据发送失败时无法感知,可能有数据丢失的情况。
集群管控操作
集群管控操作一般是用来完成资源的创建、查询、修改、删除等集群管理动作。资源包括主题、分区、配置、消费分组等等。
参考
《深入拆解消息队列 47 讲》