
Java的NIO
常见I/O模型对比
所有的系统I/O都分为两个阶段:等待就绪和操作。
比如读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
其中,等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在”干活”,而且这个过程非常快,属于memory copy,可以理解为基本不耗时。
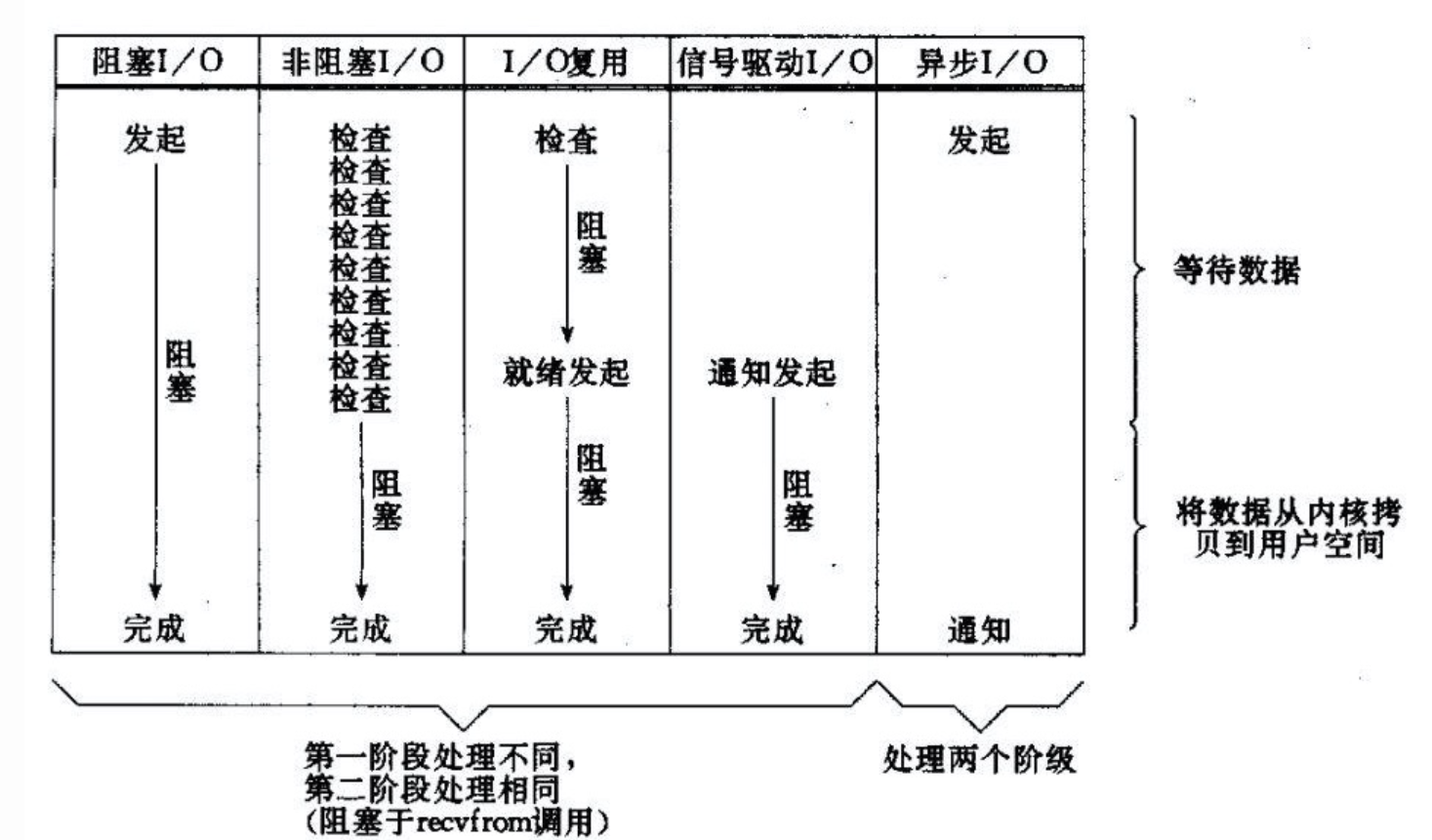
具体例子
以socket.read()为例子:
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。
对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。
最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
BIO里用户最关心“我要读”,NIO里用户最关心”我可以读了”,在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
结合事件模型使用NIO同步非阻塞特性
BIO中,之所以需要多线程,是因为在进行I/O操作时,无法估计什么时候完成,只能等待,即使通过估算算出来一个大概的时间,也无法通过socket.read()和socket.write()进行返回,所以另外开启一个新的线程是最好的解决办法。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
如何使用单线程处理所有I/O
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
首先需要注册当这几个事件到来的时候所对应的处理器,然后在合适的时机告诉事件选择器:我对这个事件感兴趣。例如,对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于accept,一般是服务器刚启动的时候;而对于connect,一般是connect失败需要重连或者直接异步调用connect的时候。
其次,用一个死循环选择就绪的事件,会执行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大胆地在一个while(true)里面调用这个函数而不用担心CPU空转。
一个最简单的Reactor模式的代码如下:
1 | interface ChannelHandler { |
优化线程模型
NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。
而且不开多线程,连接数大的时候减少了线程切换。
真正需要的线程:
- 事件分发器,单线程选择就绪的事件。
- I/O处理器,包括connect、read、write等,这种纯CPU操作,一般开启CPU核心个线程就可以。
- 业务线程,在处理完I/O后,业务一般还会有自己的业务逻辑,有的还会有其他的阻塞I/O,如DB操作,RPC等。只要有阻塞,就需要单独的线程。
Java的Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。
另外连接的处理和读写的处理通常可以选择分开,这样对于海量连接的注册和读写就可以分发。虽然read()和write()是比较高效无阻塞的函数,但毕竟会占用CPU,如果面对更高的并发则无能为力。
NIO在服务端对于解放线程,优化I/O和处理海量连接方面有一定的优势。
常见的客户端BIO+连接池模型,可以建立n个连接,然后当某一个连接被I/O占用的时候,可以使用其他连接来提高性能。
但多线程的模型面临和服务端相同的问题:如果指望增加连接数来提高性能,则连接数又受制于线程数、线程很贵、无法建立很多线程,则性能遇到瓶颈。
连接顺序请求的Redis
对于Redis来说,由于服务端是全局串行的,能够保证同一连接的所有请求与返回顺序一致。这样可以使用单线程+队列,把请求数据缓冲。然后pipeline发送,返回future,然后channel可读时,直接在队列中把future取回来,done()就可以了。
Proactor与Reactor
一般情况下,I/O 复用机制需要事件分发器(event dispatcher)。事件分发器的作用,即将那些读写事件源分发给各读写事件的处理者,开发人员在开始的时候需要在分发器那里注册感兴趣的事件,并提供相应的处理者(event handler),或者是回调函数;事件分发器在适当的时候,会将请求的事件分发给这些handler或者回调函数。
涉及到事件分发器的两种模式称为:Reactor和Proactor。 Reactor模式是基于同步I/O的,而Proactor模式是和异步I/O相关的。
在Reactor模式中,事件分发器等待某个事件或者可应用或某个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。
而在Proactor模式中,事件处理者(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区、读的数据大小或用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分发器得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。
举例来说,在Windows上事件处理者投递了一个异步IO操作(称为overlapped技术),事件分发器等IO Complete事件完成。这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。
Reactor中实现读
- 注册读就绪事件和相应的事件处理器。
- 事件分发器等待事件。
- 事件到来,激活分发器,分发器调用事件对应的处理器。
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
Proactor中实现读
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分发器等待操作完成事件。
- 在分发器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分发器读操作完成。
- 事件分发器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分发器。
两个模式的相同点,都是对某个I/O事件的事件通知(即告诉某个模块,这个I/O操作可以进行或已经完成)。在结构上,两者也有相同点:事件分发器负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调handler;不同点在于,异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read 或 can write)。
参考
《美团技术团队》