
数据该如何迁移
数据迁移需要满足以下几点:
- 迁移的过程中,要保证新数据可以写入
- 迁移后,新旧数据库数据要一致
- 迁移过程中可以回滚
下面给出几个具体的迁移方案。
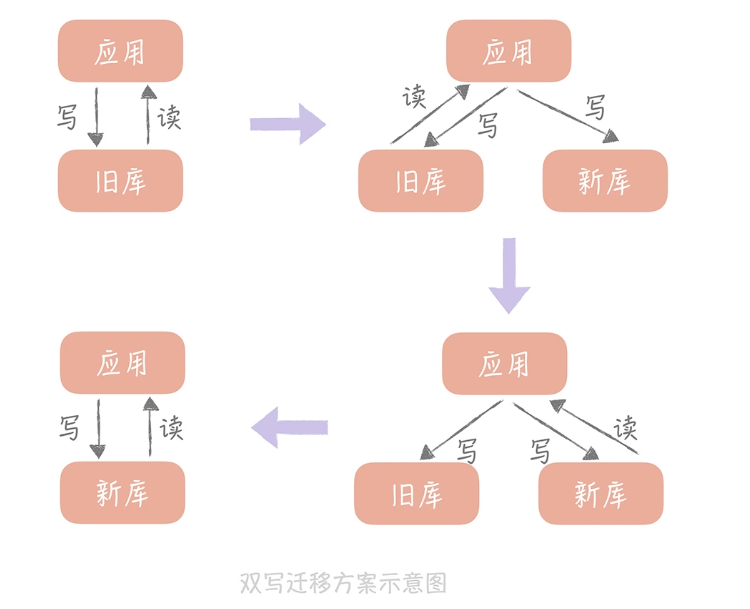
“双写”方案
1、将新的库配置为源库的从库用来同步数据
2、改造业务代码,在数据写入的时候不仅要写入旧库也要写入新库。同时要保证在写入新库失败的数据被单独记录,以便后续添加。
3、校验数据了,这里只抽取部分数据。
4、将流量切换到新库,最好采用灰度的方式,即先切10%的流量过去,然后50%,慢慢加到100。
5、如果有问题,要将流量切回之前的库。
6、如果没有问题,将双写改为只写新库。
级联同步方案
1、先将新库配置为旧库的从库,用作数据同步
2、再将一个备库配置为新库的从库,用作数据的备份
3、等到三个库的写入一致后,将数据库的读流量切换到新库
4、然后暂停应用的写入,将业务的写入流量切换到新库
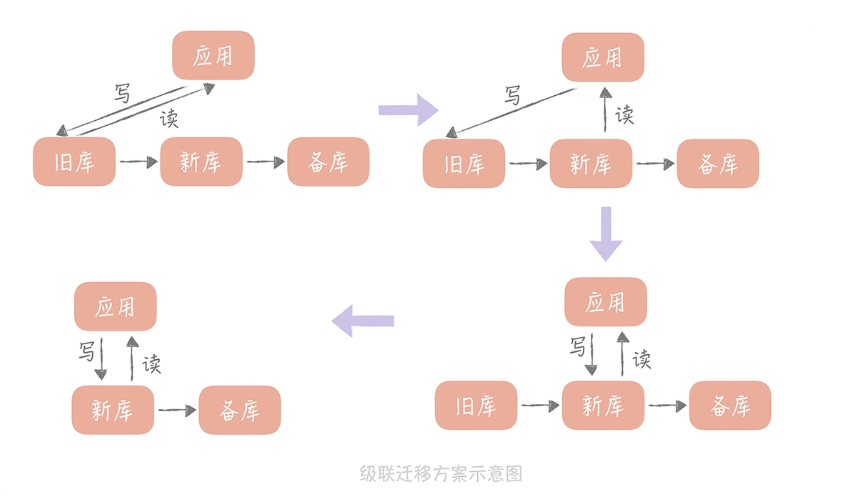
但是这里的一个缺点是,切换时要暂停应用的使用,所以要选择低峰期来执行。
数据迁移时如何预热缓存
上述的两种方案也可以在迁移缓存时使用,但是需要注意,直接在新的服务上加一个空的缓存,有可能会导致数据库宕机,所以,缓存迁移的重点是保持缓存的热度。
使用副本组预热缓存
一般的数据写入流程是写入 Master、Slave 和所有的副本组,而在读取数据的时候,会先读副本组的数据,如果读取不到再到 Master 和 Slave 里面加载数据,再写入到副本组中。
这样,我们可以直接在云上部署一个副本组,如果查不到就去旧的机房去查询缓存,然后写入副本组。当副本组数据足够多时,缓存的迁移也就完成了。
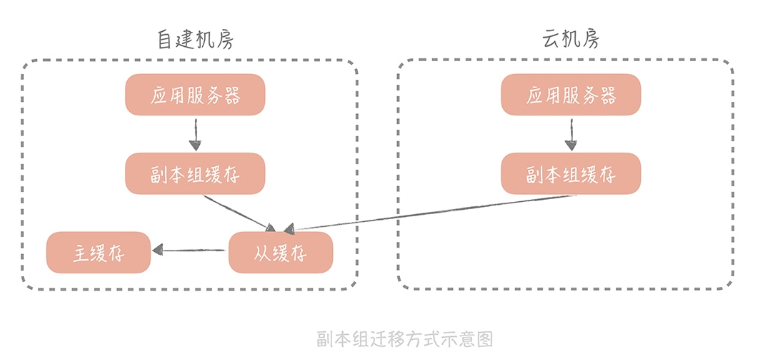
不过这里要注意,存在跨网络的调用,可能接口的速度会受到影响。
改造副本组方案预热缓存
1、在云上部署多组缓存的副本组,自建机房在接收到写入请求时,会优先写入自建机房的缓存节点,异步写入云上部署的缓存节点;
2、在处理自建机房的读请求时,会指定一定的流量(比如 10%)优先走云上的缓存节点,这样虽然也会走专线穿透回自建机房的缓存节点,但是流量是可控的;
3、当云上缓存节点的命中率达到 90% 以上时,就可以在云上部署应用服务器,让云上的应用服务器完全走云上的缓存节点就可以了。
参考
《高并发系统设计》