
拥塞控制原理
拥塞原因与代价
情况1:两个发送方和一台具有无穷大缓存的路由器
两台主机(A和B)都有一条连接,且这两条连接共享源与目的地之间的单跳路由,如下图所示:
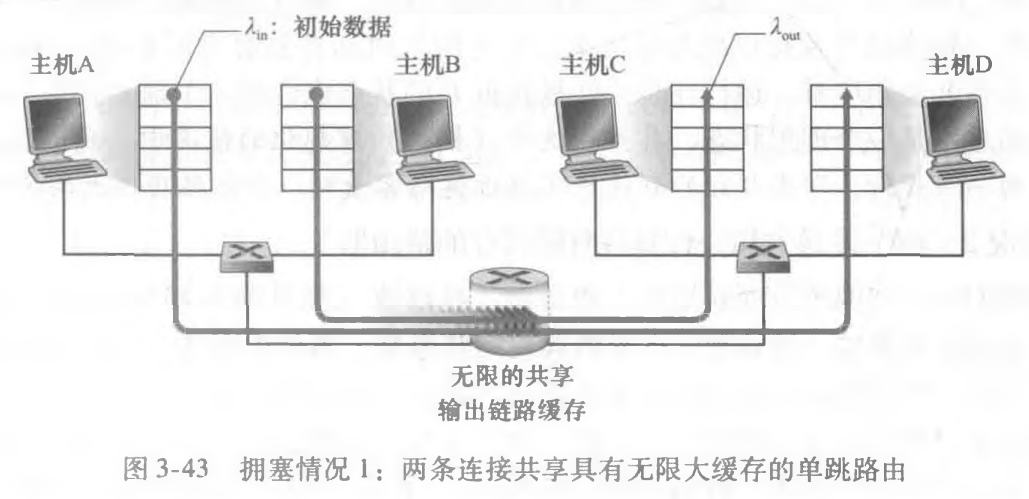
由于路由器的缓存是无限制的,那么发送方的发送速率达到一定程度,路由器中的平均排队分组数就会无限增长,源与目的地之间的平均时延也会变成无穷大。
情况2:两个发送方和一台具有有限缓存的路由器
这里对情况1稍微做一些修改,假定路由器的缓存容量是有限的。这种假设的结果是,当分组到达一个已满的缓存时会被丢弃。然后我们假设连接可靠,即分组在路由器中被丢弃时,会重发。
假设发送方知道路由中缓存容量,只有在路由未满时才发送,那么就不会导致分组丢失。
但一种更为真实的情况是,发送方并不知道,那么在缓存满时发送分组,带来的代价就是需要重新发送。而且存在一种情况,分组发出但是未丢失,还在排队当中,发送方因超时重新发送了分组,那么就会导致接收方需要丢弃一个重传分组,带来了不必要的开销。
这里就看出拥塞的两个代价,发送方需要重传丢失的分组,而且发送方可能重传不必要的分组。
情况3: 4个发送方和具有有限缓存的多台路由器及多跳路径
考虑下图的情况:
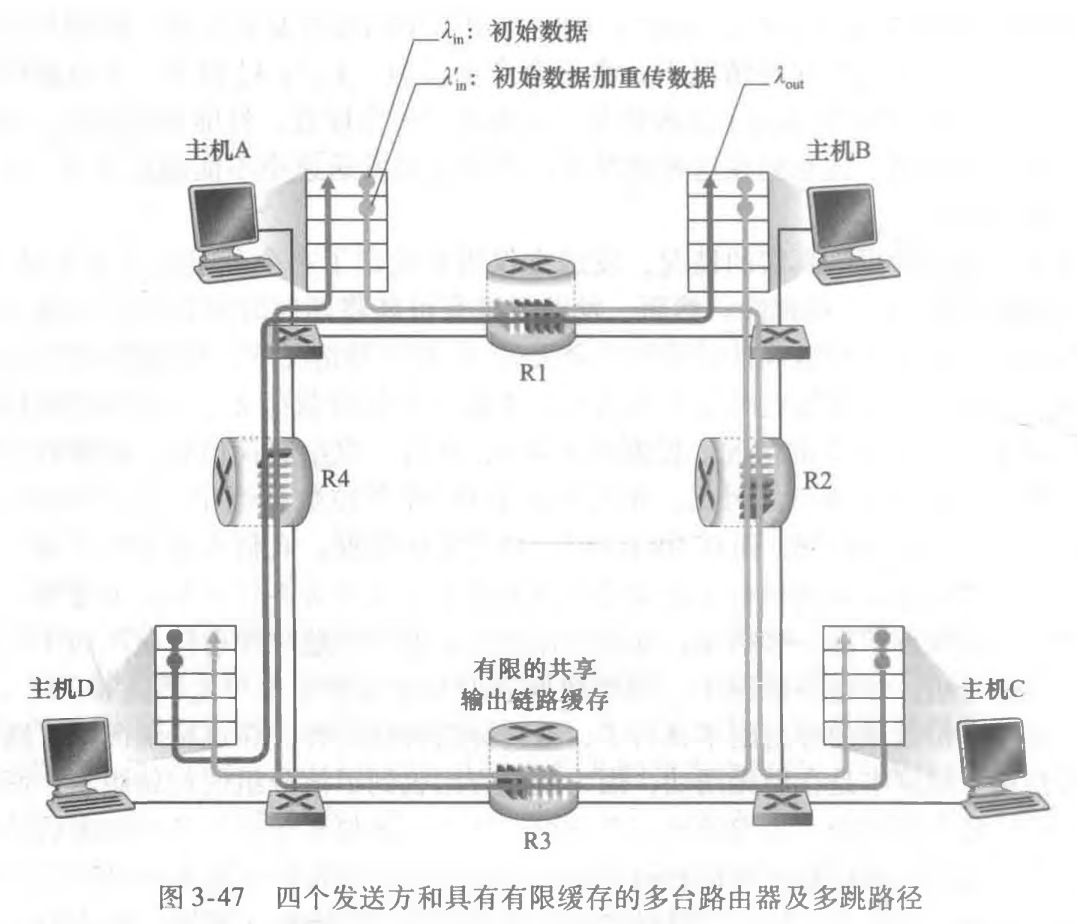
由于路由器R2的缓存容量是有限的 ,那么当A-C通信,B-D通信时,这两者势必会争抢缓存,一种极端的情况是A-C占据了所有的缓存,导致B-D流量几乎为0,导致分组丢失。
还会导致资源浪费的一个点是,如果R2丢弃B-D的分组,那么R3所做的转发也就成了无用功,导致资源浪费。
拥塞控制方法
端到端拥寒控制
在端到端拥塞控制方法中,网络层没有为运输层拥塞控制提供显式支持。即使网络中存在拥塞,端系统也必须通过对网络行为的观察(如分组丢失与时延)来推断。
TCP采用端到端的方法解决拥塞控制,因为IP层不会向端系统提供有关网络拥塞的反馈信息。TCP报文段的丢失(通过超时或3次冗余确认而得知)被认为是网络拥塞的一个迹象,TCP会相应地减小其窗口长度。
网络辅助的拥塞控制
在网络辅助的拥塞控制中,路由器向发送方提供关于网络中拥塞状态的显式反馈信息。这种反馈可以简单地用一个比特来指示链路中的拥塞情况。
对于网络辅助的拥塞控制,拥塞信息从网络反馈到发送方通常有两种方式,如下图
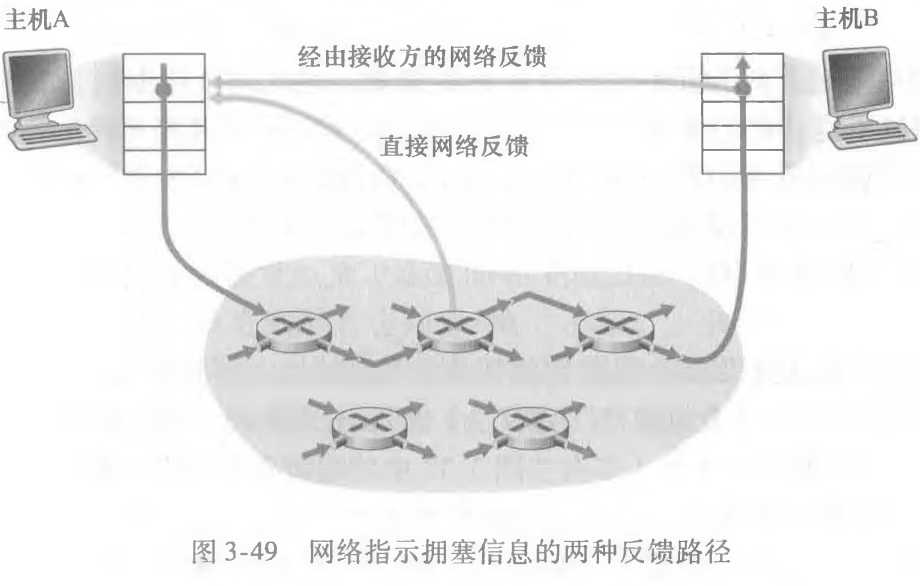
直接反馈信息可以由网络路由器发给发送方。这种方式的通知通常采用了一种阻塞分组(choke packet) 的形式(主要是说: “我拥塞了!”)。
更为通用的第二种形式的通知是,路由器标记或更新从发送方流向接收方的分组中的某个字段来指示拥塞的产生口 一旦收到一个标记的分组后,接收方就会向发送方通知该网络拥塞指示。