
MySQL读写分离存在的问题
在MySQL的一主多从的架构中,往往有以下两种设计方案:
1、由客户端决定连接哪个数据库
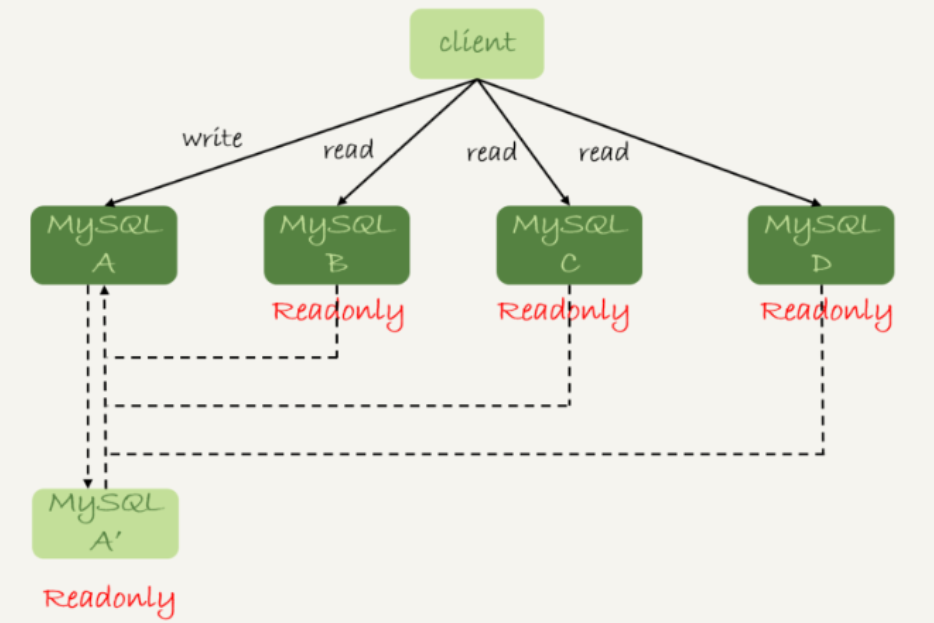
2、由代理决定请求分发到哪一个数据库
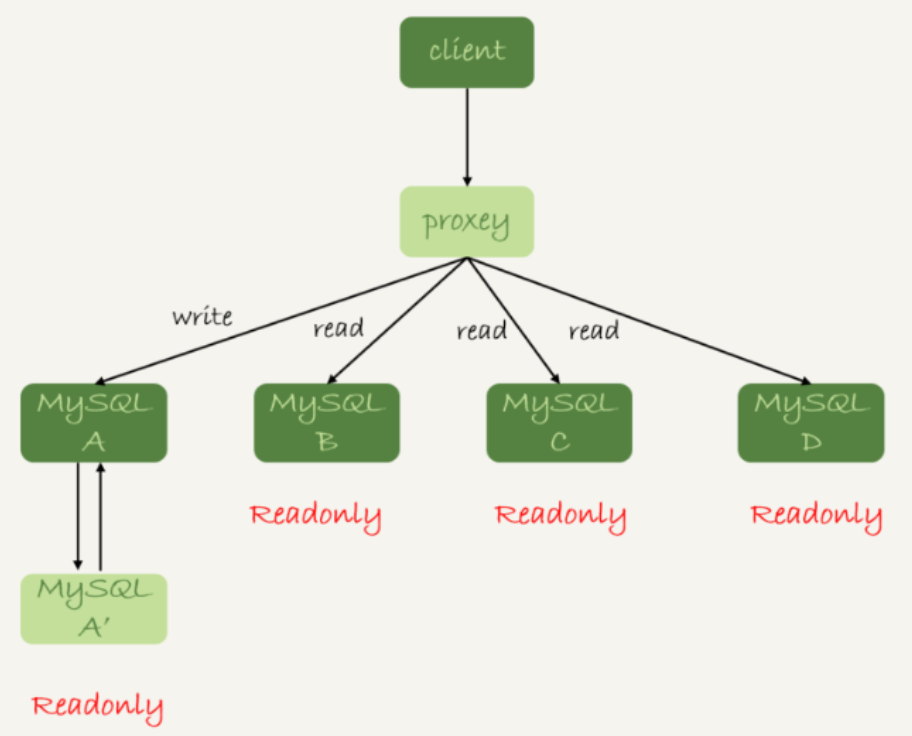
但不管是哪种方案,都存在过期读的问题,即主库和从库存在一定的时延,用户刚做一个修改,然后立马发起查询,就有可能查到过期数据。以下给出几种解决方案。
强制走主库
该方案将请求分为了两类:
1、必须拿到最新数据的,就强制走主库查询。
2、对于可以读取到旧数据的,就走从库查询。
Sleep 方案
该方案的设计很简单,读从库之前先sleep一段时间。
它假设大多情况下主备延迟在1秒之内,所以简单的sleep可以拿到最新的数据。
判断主备无延迟方案
这里有几种办法,第一种是从库查询前,先判断seconds_behind_master是否已经等于0。如果还不等于0 ,那就必须等到这个参数变为0才能执行查询请求。
第二种和第三种方案,都是通过对比主库和从库的日志执行位点来判断是否有延迟,即通过对比主库和从库执行的日志,来判断,要比对比时间准确。
但是这里也存在问题,主库存在一部分日志刚刚提交,而从库还没收到该日志,也会导致有一定的延迟。
配合semi-sync
这里引入了半同步复制,semi-sync做了这样的设计:
- 事务提交的时候,主库把binlog发给从库;
- 从库收到binlog以后,发回给主库一个ack,表示收到了;
- 主库收到这个ack以后,才能给客户端返回“事务完成”的确认。
这样可以保证如果从库发送过确认消息,就代表收到了日志。这样,semi-sync配合前面关于位点的判断,就能够确定在从库上执行的查询请求,可以避免过期读。
但是该方案适合一主一从的架构,如果一主多从,那么一个从库响应,就默认已经同步成功,但是其他从库不确定。如果此时查询走的是其他从库,则还是会有问题。
而且存在一种情况,如果高峰期日志写的很快,可能会导致主库位点一直不一致的情况,就出现从库迟迟无法响应的问题。
等主库位点方案
该方案涉及到以下命令:
1 | select master_pos_wait(file, pos[, timeout]); |
该命令在从库执行,参数file和pos指向从库上的某个文件以及对应位置,timeout可选,表示这个函数最多的等待时间。
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务。
那么我们的查询逻辑变为以下:
1、主库执行完事务后,执行show master status得到当前主库执行到的File和Position;
2、从库查询之间,先执行master_pos_wait(File,Position)
3、如果返回 >= 0的正整数,则在该从库执行查询,否则到主库查询。
GTID方案
该方案和上述等主库位点方案思路一致,只不过是后续MySQL做了优化。
我们不再需要去主库执行show master status来获取位点,而是主库执行完后,直接返回一个事务的GTID,然后从库执行时,只需要在从库执行select wait_for_executed_gtid_set(gtid1, 1),该命令也是用于等待主从同步的命令。
参考
《MySQL45讲》