
空闲空间管理
这一部分,书中做了一些假设:
1、如果请求内存,就需要指定请求内存的大小,而释放该内存则不用指定大小。
2、只考虑外部碎片,不考虑因分配空间稍微大于请求内存而造成的内部碎片。
3、内存一旦被分配给用户,那么它就不可能被重定位。即这块内存分配给用户后,除非用户调用free函数,否则无法被其他人使用。
4、分配程序管理的内存区域是连续的,而且还可以增大这块区域。
底层机制
1、分割与合并
假如内存中空闲状态如下图:

那么它对应的空闲链表如图:
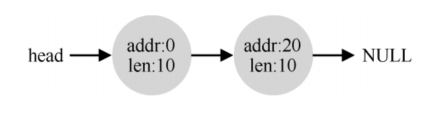
这也就意味着,任何长度大于10字节的分配请求都会失败。
如果请求分配的内存小于10字节,那么它会找到一块满足的空间区域,然后进行分割,第一块分给用户,剩下的加入空闲列表。
而用户在调用free时,它并不是把用户使用的那块区域直接加入,而是会看用户释放的空间左右两端是否是空闲的,如果是,则进行合并。
比如参考第一张图,如果用户释放中间用掉的10字节,它会变为如下:
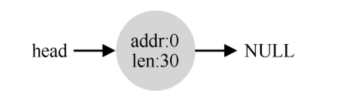
而不是

2、追踪已分配空间的大小
由于在释放对应区域空间时,并不需要指出大小,这是因为在大多数分配程序都会在头块中保存一些额外的信息,头块位于内存中,就在返回的内存区域前面。

这里释放的时候会释放头块加具体的内存空间,那么意味着在申请内存时,申请的大小也是头块加用户指明的大小。
内存分配的基本策略
1、最优匹配:找到和用户申请大小最接近的一块区域,分配给用户。但是他需要遍历所有的空闲列表,性能差一点。
2、最差匹配:找最大的空闲区域,分割并分配给用户。会导致过量碎片,而且性能不好。
3、首次匹配:找到第一个足够大的块,分配给用户。不需要全部遍历,但可能会导致开头的部分有很多的小块,因此,如何管理空闲列表顺序就变的比较重要。
一种解决办法:一种方式是基于地址排序,保持空闲块按内存地址有序,会让合并变得容易,减少内存碎片。
4、下次匹配:每一次都从上一次分配完成的地址开始往后遍历。
参考
《操作系统导论》