
order by是怎么工作的
假设我们现在有如下表,其中id是主键,city上有普通索引。
| id | city | name | age |
|---|---|---|---|
| 1 | 杭州 | 张三 | 22 |
| 2 | 杭州 | 李四 | 23 |
| 3 | 郑州 | 王五 | 24 |
| …… | …… | …… | …… |
现在需要查出city为杭州的人的性命和年龄,并按照年龄排序的前100个人。那么sql语句如下:
1 | select city, name, age from t where city='杭州' order by name limit 100; |
全字段排序
先初始化sort_buffer,这是一块用于排序的内存,然后确定放入city,name,age三个字段。
之后,会在city索引树中找到值为杭州的记录,然后去主键索引取这一行的值存入sort_buffer,直到city不为杭州。
然后在sort_buffer中使用快排根据name字段进行排序,对排序结果取前100行返回给客户端。
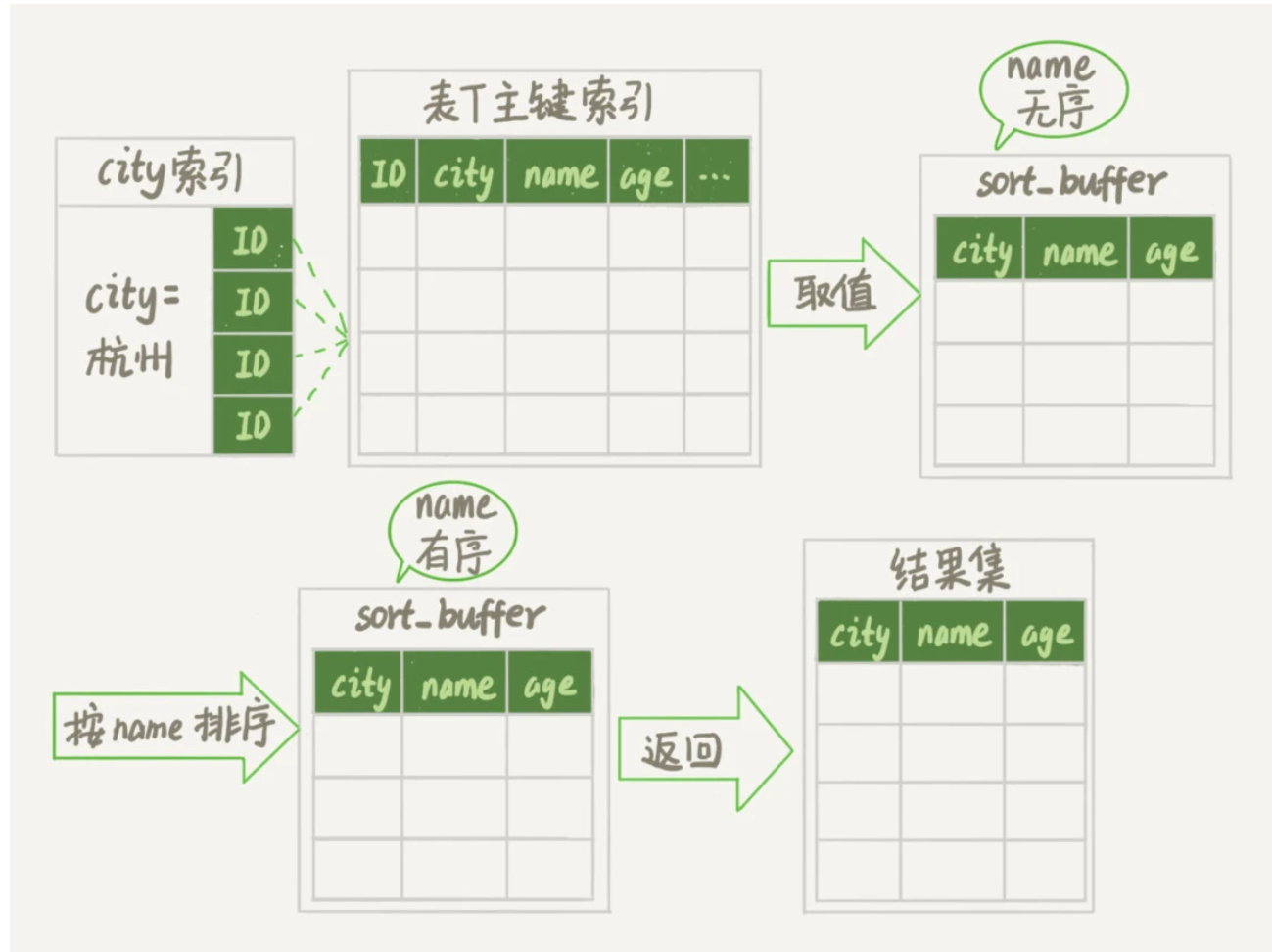
其中,如果取出的数据量太大,无法存入sort_buffer,则需要利用磁盘临时文件辅助排序。
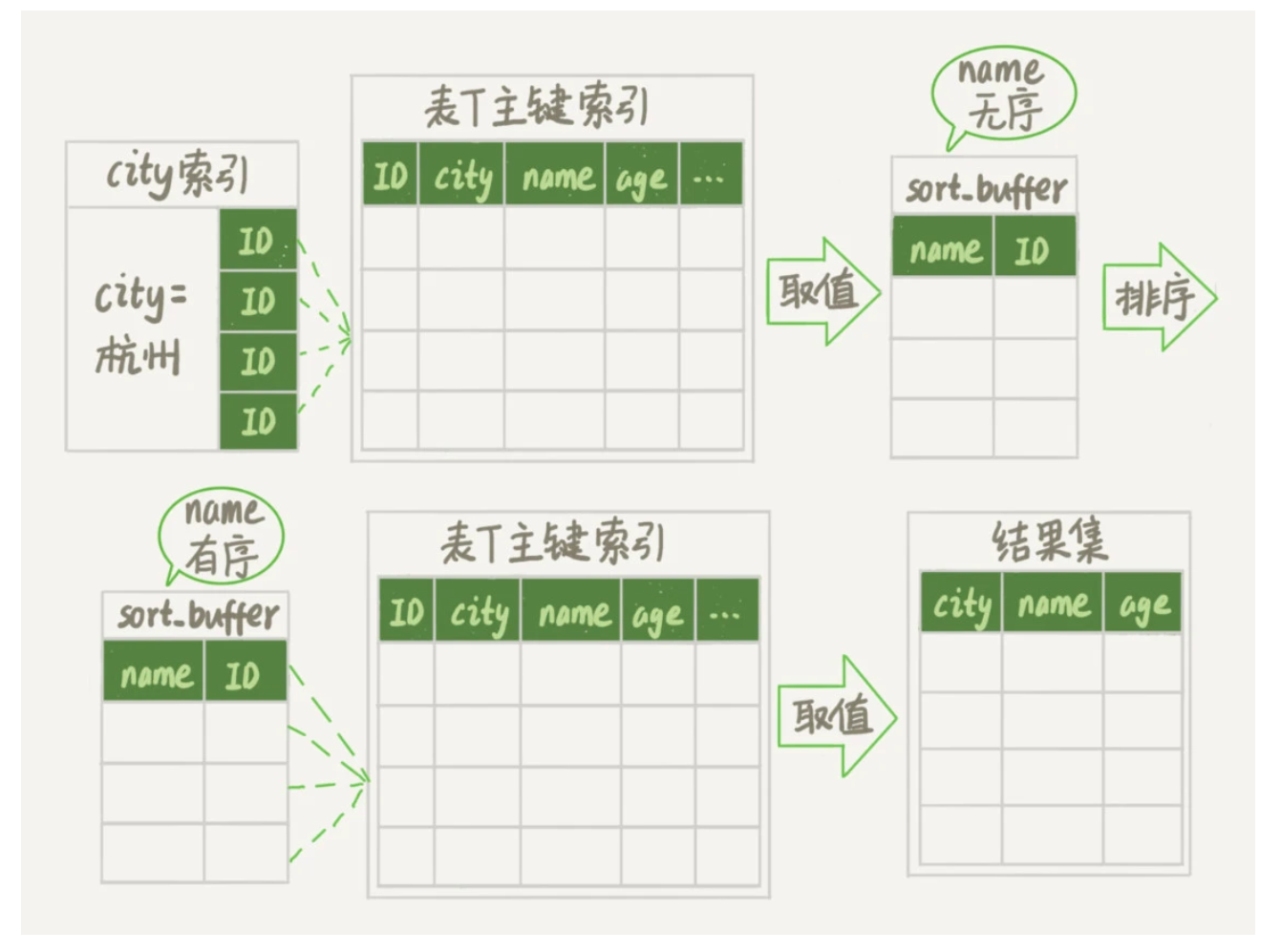
rowid排序
上述情况可以把所有数据都放入sort_buffer中进行排序,但是如果不能全部放入,会把原来的文件分成多份,借助临时文件来进行归并排序。如果一行的数据量太大,则要分的份数太多,会影响性能。
MySQL提供了一个参数,max_length_for_sort_data用于限制排序的行数据的长度。比如我们设置它为16,如果sort_buffer在初始时确定放入字段的长度超过16,则会采用rowid排序。
现在的排序过程如下:
初始化sort_buffer,确定放入id和name字段(只放入排序相关的字段)。
这之后的步骤与上面的排序过程类似,不过在sort_buffer内排序完成后,需要根据id去主键上取city,name,age字段后,再返回给用户。相当于多了一次回表操作。
全字段排序和rowid排序
如果内存足够大,则会优先使用全字段排序,因为可以减少一次回表操作,否则会采用rowid排序。
这里也体现了MySQL的一个设计思想:能用内存就用,尽量减少磁盘访问。
优化
上述SQL需要排序是因为数据是无序的,但是如果我们保证了从city索引中取出的数据就是按name有序的,就可以省略掉排序的过程。
所以我们可以建立一个联合索引 (city, name),然后执行流程如下:
1、从联合索引中找到city为杭州的记录。
2、去主键索引取name、city、age三个字段的值,作为结果集的一部分直接返回。
3、一直重复上述步骤,直到city不为杭州或者够100条记录。

这样,就不需要使用临时表了。
如果创建了(city,name,age)的联合索引,则还可以省去回表的操作,进一步优化查询时间。但是会导致索引占用空间过多。
参考
《MySQL45讲》