
MySQL索引
索引的出现其实就是为了提高数据查询的效率。
索引常见的模型
哈希表
适合等值查询,不适合范围查询。因为会出现哈希冲突,冲突后采用链地址法解决。就会导致发生冲突后要遍历整个链表。
有序数组
适合等值查询以及范围查询。有序数组在单值查询可以使用二分法快速查找,范围找到一个然后往左右遍历即可,但是它插入数据时要维护这个有序数组就比较麻烦,适合用于静态存储引擎。
搜索树
二叉搜索树的特点是:左边小,右边大(相对根节点)查找效率和二分一样,O(LogN)。但是为了保证这个效率,就需要保证它是平衡二叉树(考虑插入数据是正序或者倒序情况,会退化成链表),为了确保平衡,插入时间复杂度也是O(LogN)
多叉树:孩子节点从左到右依次递增。
二叉树搜索效率最高,但是往往采用多叉树,因为索引还要写入磁盘,意味着我们查询索引可能也要读取磁盘。考虑一种情况,100万数据量,那么二叉树高20,如果这些索引没有在内存当中,那么就需要去读取20个数据块。
每次从磁盘读取数据都是按照数据块来读取的,而不是仅仅查找那一条记录。而MySQL并不是一开始就把所有的索引都加载到内存当中,而是按需加载。MySQL有一个缓冲池,当需要访问索引时,会先在缓冲池中查看有没有,如果没有就从磁盘读取,然后写入缓冲池中。
N叉树的N一般是1200。考虑到树根的数据块总是在内存中,一个10亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。
InnoDB索引模型
假如有如下表:
| ID | k | name |
|---|---|---|
| 100 | 1 | null |
| 200 | 2 | null |
| 300 | 3 | null |
| 500 | 5 | null |
| 600 | 6 | null |
其中ID是主键,k上有索引。那么它的索引结构大致如下:
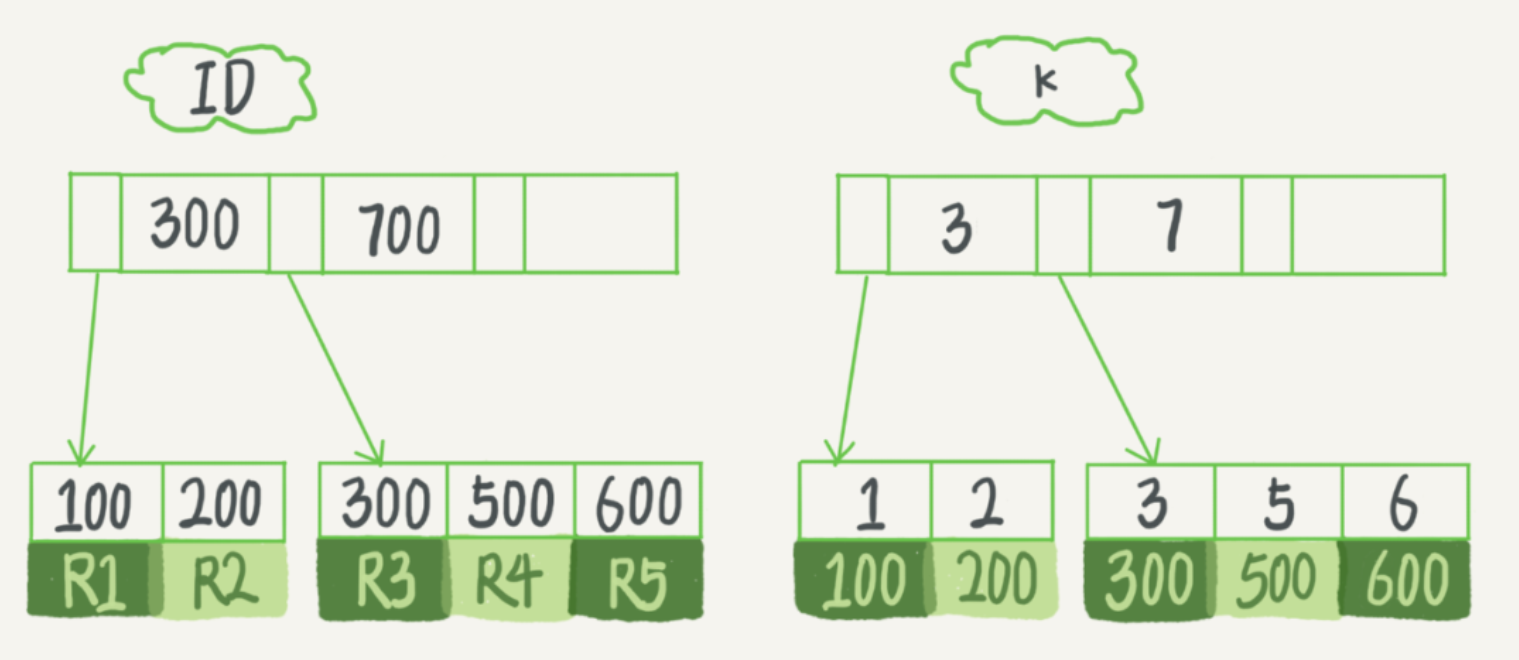
在InnoDB中,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为二级索引(secondary index)。
其中,如果是按照主键索引查询,那么只会搜索上图的第一颗树,然后找到对应记录直接返回行数据即可。但是如果是按照k这个索引来查询,那么会现根据k索引查找到对应数据的主键,然后去第一颗树中查找对应的实际数据。
索引维护
索引的插入可能会导致数据的其他数据的移位,在极端情况下,如果要插入的索引页满了,那么就会导致页分裂。这个页分裂的过程就是B+树页分裂的过程。
最重要的一点,B+树的索引是建立在数据所在的数据页上的,而不是直接建立在数据。其实通过索引找到数据页后,还要在数据页中去找具体的数据,才能返回。
回表
1 | select * from T where k between 3 and 5 |
首先在非主键索引树上找到k = 3的值,取得ID = 300,然后去主键索引树上查找ID = 300所对应的具体值。然后在非主键索引树上找下一个值,k = 5,找ID,然后拿ID去查主键索引。然后继续去下一个,发现k = 6,大于5,查找结束。
这个从非主键索引查找完去主键索引查找的过程就叫做回表。
覆盖索引
1 | select ID from T where k between 3 and 5 |
执行这个语句时,虽然会走非主键索引,但是索引的值存的是ID,即索引里面包含了所有要查询的数据,这就是覆盖索引。由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
最左前缀原则
比如我们建立了一个(姓名,年龄)的索引,那么它可以用来匹配按名字的查找,但是按照年龄就不行。这个最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
索引下推
比如我们已经建立了(姓名,年龄),此时要执行以下SQL:
1 | select * from tuser where name like '张%' and age=10 and ismale=1; |
假如数据库表数据如下:
| ID | name | age | ismale |
|---|---|---|---|
| 1 | 李四 | 2 | 1 |
| 2 | 123 | 10 | 1 |
| 3 | 张三 | 10 | 1 |
| 4 | 张三 | 10 | 1 |
| 5 | 张三 | 30 | 1 |
| 6 | 张六 | 40 | 0 |
在执行这条语句时,如果没有索引下推,则每次按索引找到姓张的后,都需要回表去查看对应的一整行数据,来判断后两个字段是否一致。但是有了索引下推,可以在这里直接判断age是否满足条件,可以减少回表的次数。注意,这里的索引是联合索引,如果没有下推,即便是索引里有age字段,也不会进行判断。
参考
《MySQL45讲》