
Redis的主从复制
在redis中,用户可以通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制另一个服务器,被复制的服务器就是主服务器,另一个就是从服务器。
旧版复制功能的实现
旧版指的是2.8版本以前的复制,分为两个操作,同步和命令传播。
同步
将从服务器的状态更新至主服务器当前所处的状态。
同步过程如下:
1、从服务器发起同步请求(发送SYNC命令)。
2、主服务器在后台生成RDB文件,并使用一个缓冲区记录生成RDB文件时产生的新数据。
3、当生成完成后,将RDB文件发送给从服务器。从服务器接收并载入RDB文件。
4、将缓冲区数据发送给从服务器,从服务器接收并写入。
命令传播
主服务器状态被修改,导致主从状态不一致,用命令传播使他们一致。
这个并不会像上面那样生成RDB文件,只会发送一条命令。
比如刚刚同步完数据,目前主从数据一致。但是主库执行了一条del命令,然后主从就不一致了,把这条del命令发给从库的行为就叫做命令传播。
旧版的缺陷
当第一次全量同步时,可以很好的完成该工作。但是当全量同步中途出错,导致同步结束,就会有一个问题,当从库重连后,需要重新进行全量同步,还需要生成新的RDB文件,而生成RDB文件需要占用大量的cpu资源,内存和磁盘I/O,而且主从传输RDB文件还会占用网络带宽。所以如果中途出现意外,就需要进行新的全量同步,这样效率很低。
新版功能的实现
新版的复制采用PSYNC命令来代替SYNC命令。
PSYNC具有完整同步和部分重同步两种,完整同步和SYNC的一致,而部分重同步在断线重连后,如果条件允许,会接着上一次的同步,或者只同步在断线期间产生的新数据。
部分重同步实现
部分重同步由以下三部分构成:
1、主服务器的复制偏移量和从服务器的复制偏移量。
2、主服务器的复制挤压缓冲区。
3、服务器运行ID。
复制偏移量
执行复制时,主从服务器都会维护一个偏移量,用于记录同步的位置。该偏移量可以用来判断主从是否一致。如果一致,那么偏移量应该相等。一个具体的例子,比如主服务器的偏移量为100,三个从服务器此时的偏移量都是100,则说明主从都是一致的。此时主服务器又产生了20字节的数据需要同步,那么主服务器同步完后会在偏移量上加20,此时是120,从服务器同步成功后,也会在偏移量上加20,如果有一个从服务器同步失败,那么它的偏移量就还是100。
复制积压缓冲区
在主服务器同步的过程中,它不仅会把数据发送给从服务器,也会写入复制积压缓冲区。这是一个队列,默认大小为1mb。而且写入这里边的数据都会被记录复制偏移量。
当从服务器断线重连后,如果复制偏移量之后的数据仍然在复制积压缓冲区中,那主服务就对从服务器进行部分重同步,如果复制偏移量之后的数据不在复制积压缓冲区中,那么就进行全量同步。
PSYNC命令执行时可能会遇到的情况
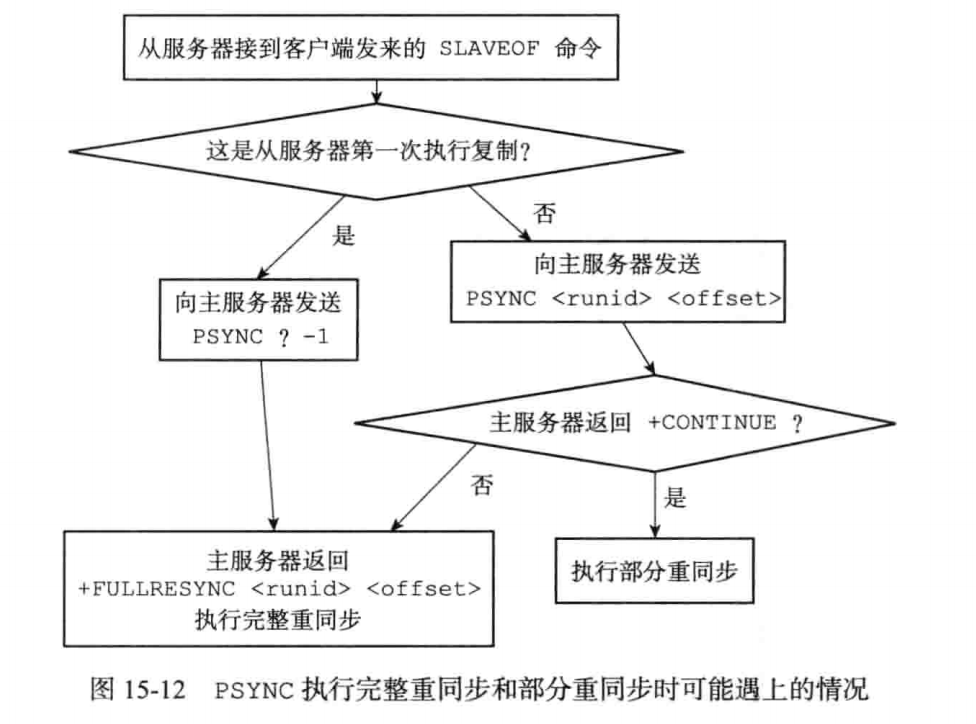
参考
《Redis设计与实现》