
Redis对象
Redis中有那些对象
redis中有简单动态字符串(SDS),双端链表,字典,压缩列表,整数集合等数据结构,但是redis并没有直接采用这些数据结构来构成键值对数据库,而是基于这些数据结构创建了一个对象系统。包含了字符串对象,列表对象,哈希对象,集合对象,有序集合对象。而且redis对象系统还实现了基于引用计数器的内存回收机制,并且通过引用计数技术实现了对象共享。
redis中每个对象都是由一个redisObject结构表示,该结构中和保存数据有关的三个属性如下:
1 | typedef struct redisObject { |
type
这个属性记录了对象的类型,该类型可以是下表中的一个。
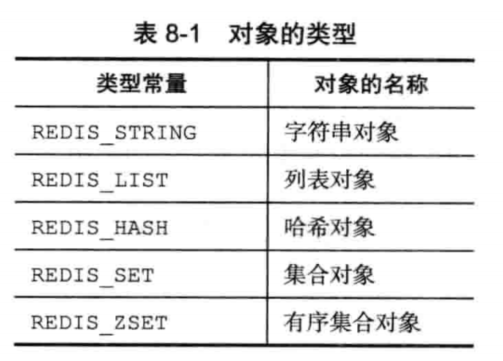
每一个数据的键,总是一个字符串对象,而值可以是上表中的任意一个。
在redis中,使用TYPE命令可以显示一个键对应值的type
encoding
记录了对象所使用的编码。即记录该对象使用什么数据结构作为底层的实现。可以是下表中的任意一个。
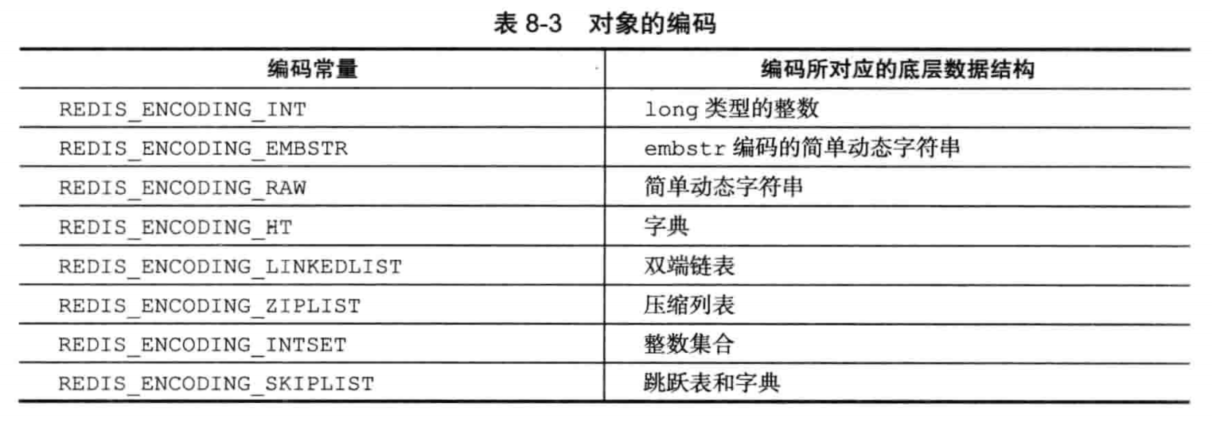
每种类型的对象至少使用了两种不同的编码,如下表所示
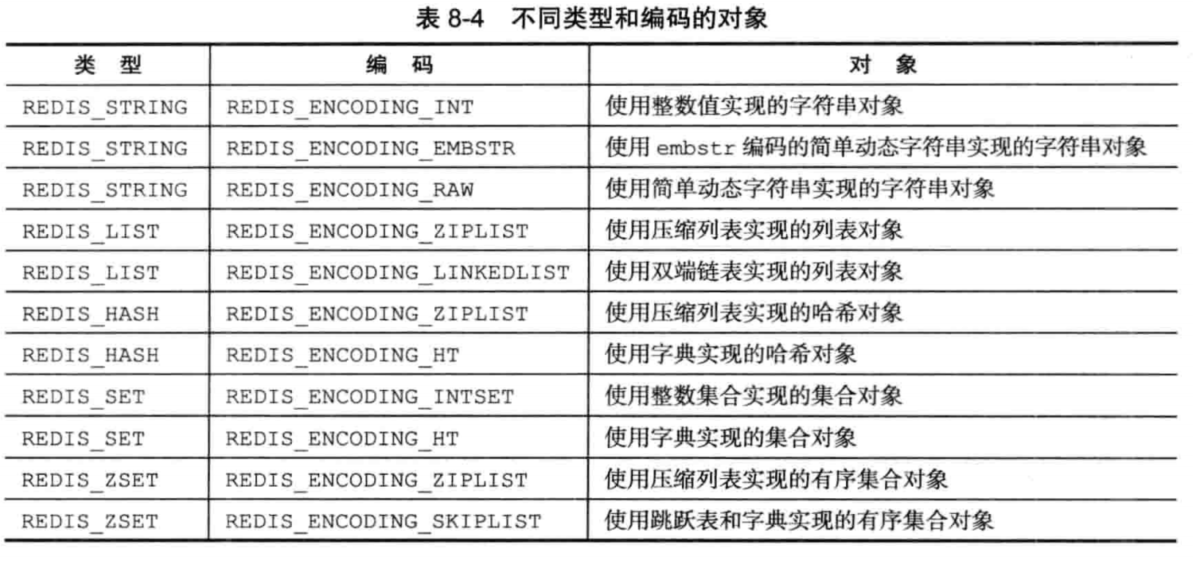
在redis中,使用OBJECT ENCODING命令可以查看一个键对应值对象的编码。
通过encoding属性设置编码,而不是固定一个对象的编码,为redis带来了极大的灵活性。因为redis可以根据不同场景选择不同的编码,以此改变底层数据结构。
字符串对象
如果字符串对象存储的是整数,并且这个整数可以用long表示,那么整数值将保存在字符串对象结构的ptr属性里面。void* 转换为long。并将字符串编码设置为int。
如果字符串对象保存的是一个字符串值,并且该值长度大于32字节,那么就是用简单动态字符串保存,如果小于32,则使用embstr编码保存。
embstr
embstar专门用来保存短字符串的一种优化编码。embstr和raw都是使用redisObject和sdshdr结构来表示字符串,但是raw需要两次内存分配来创建,而embstr只需要一次内存分配,并且是连续的地址。释放空间也一样,分别是1次和2次。
long double类型表示的浮点数也是作为字符串来保存的。
编码的转换
int类型的编码和embstr在适当条件下会被转化为raw编码。而且,redis没有为embstr编写任何修改程序,我们对次做的任何修改都会使其转化为raw编码。
列表对象
列表对象的编码可以是ziplist(压缩列表)或者linkedlist(双端链表)。
当列表对象满足所保存的所有字符串元素都小于64字节,且数量小于512个时,采用ziplist编码,否则采用linkedlist编码。
哈希对象
哈希对象的编码可以是ziplist或者hashtable。
ziplist编码的哈希对象,每当有新的值加入,程序会先将保存了键的压缩列表节点加入压缩列表的表尾,然后是将保存值的节点加入表尾。所以说,保存了键和值的节点总是挨在一起,键在前,值在后。而且先添加的键值对在表头,后添加的在表尾。
具体结构如下图:
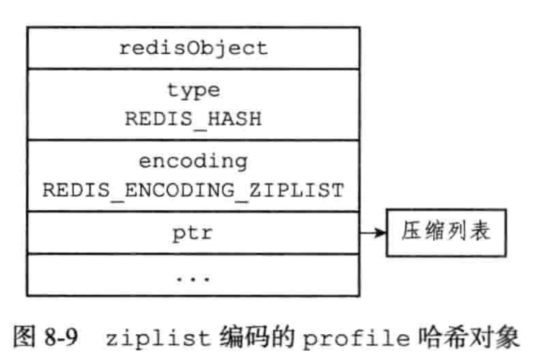
hashtable编码的哈希对象,使用字典作为底层实现。哈希对象每一个键值对都使用一个字典键值对来保存。
字典的键是一个字符串对象,保存了键值对的键。字典的每个值也是一个字符串对象,保存了键值对的值。
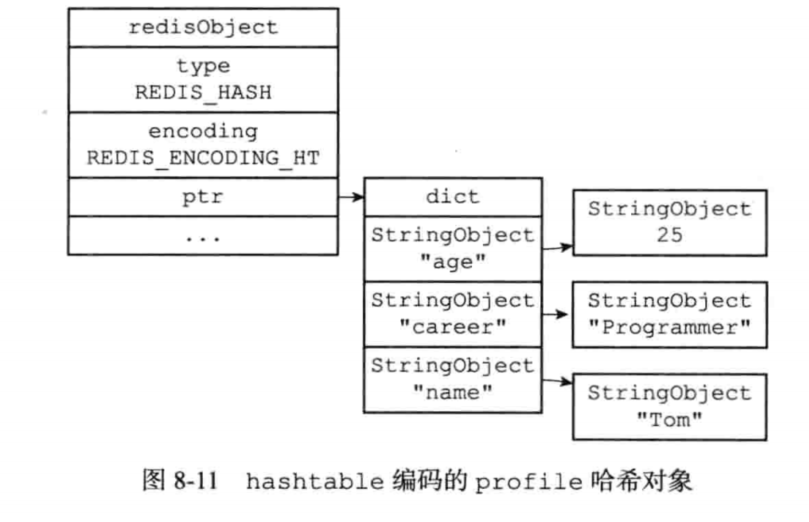
当哈希对象的所有键值对的键以及值的长度都小于64且键值对数量小于512时,使用ziplist编码,否则使用hashtable编码。
集合对象
集合对象的编码可以是intset或者hashtable。
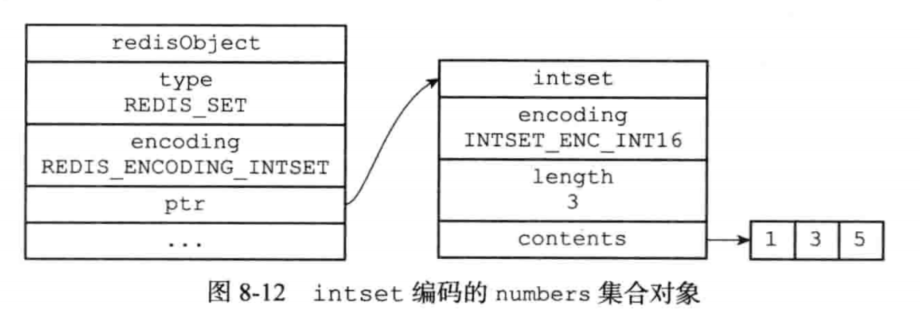
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里。
具体结构如下:
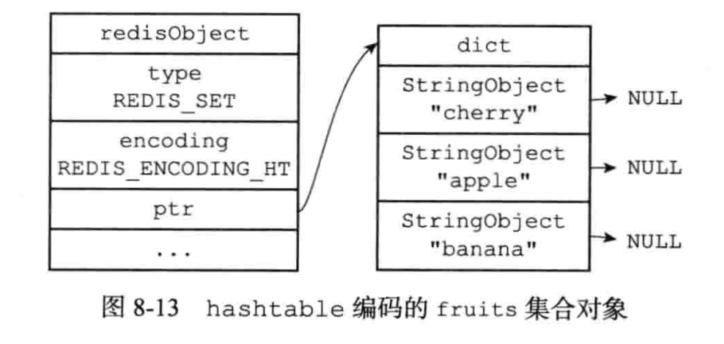
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为null。hashtable编码如果要取值,则只用取出来键即可。
执行完下面语句的结构如下图
1 | SAD Dfruits "apple" "banana" "cherry" |
当集合对象保存的都是整数,且数量不超过512个时,采用intset编码,否则采用hashtable编码。
有序集合对象
有序集合编码可以是ziplist或者skiplist。
ziplist编码的有序集合对象使用压缩列表作为底层,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(number),第二个元素保存元素的分值(score)。
压缩列表内元素按照分值大小从小到大排序,分值较小的元素被放置在靠近表头的方向,较大的放在表尾。
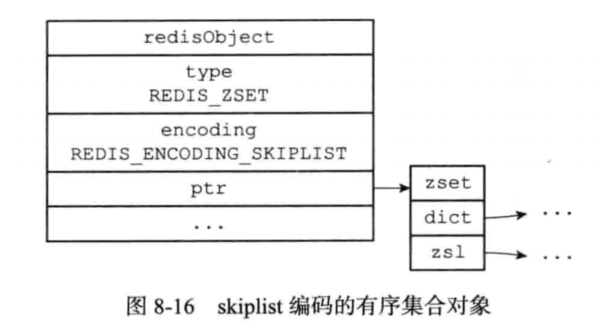
skiplist编码的有序集合对象使用zset结构作为底层实现。一个zset包含了一个字典和一个跳跃表,具体结构如下:
1 | typedef struct zset { |
zset结构中的zsl跳跃表按分值从小到大保存了所有的集合元素,跳跃表的每个节点保存了一个集合元素:跳跃表节点的object属性保存了元素成员,而跳跃表节点的score保存了分值。通过跳跃表可以对集合实现范围操作。
zset中的字典为有序集合创建了一个从成员到分值的映射,字典中的每一个键值对都保存了一个集合元素,键是元素成员,值的成员对应的分值(score)。
zset会同时使用跳跃表和字典保存集合元素,但这两种结构会通过指针共享相同元素的成员和分值,所以不会浪费内存。
为什么同时使用跳跃表和字典?
如果单纯使用字典,能保留在o(1)的时间复杂度内查找到某成员,但是字典是无序的,对于范围查找则效率不高,而跳跃表因为有序所欲进行范围查找很快。如果单纯使用跳跃表,那么就无法完成在o(1)的时间复杂度内查找到某成员。
一个具体的例子:
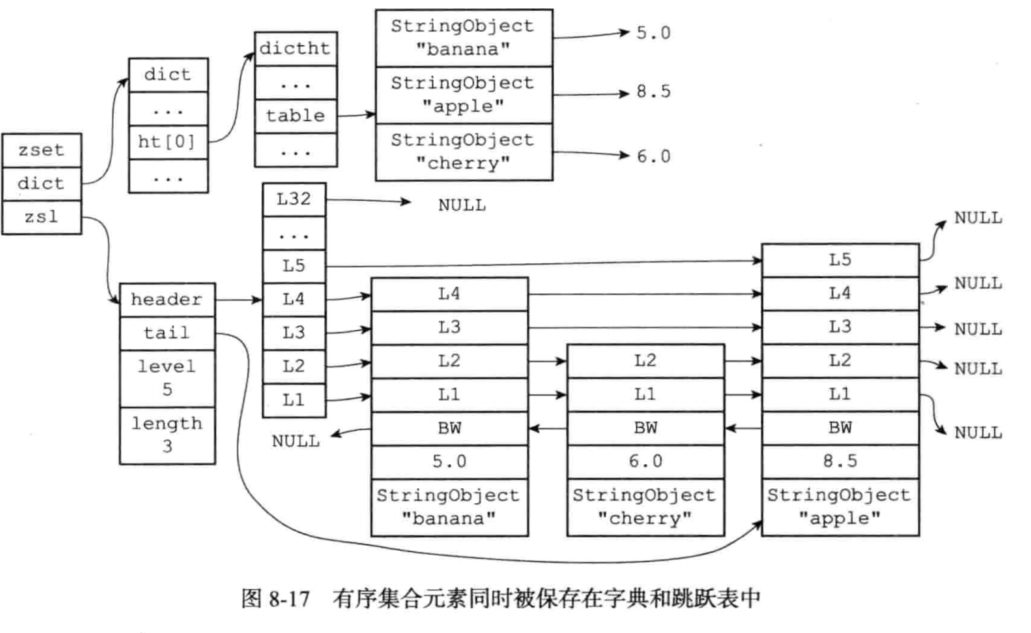
当有序集合元素数量小于128个,同时所有元素成员长度小于64字节时,使用ziplist编码,否则使用skiplist编码。
参考
《Redis设计与实现》