
Redis设计与实现之基本数据结构(三)
跳跃表
使用场景
跳跃表在大多数时间内可以与平衡树媲美,而且跳跃表的设计要比平衡树简单,所以采用跳跃表。
在Redis中,使用跳跃表作为有序集合的底层实现。如果一个有序集合的元素数量比较多,或者有序集合的成员是比较长的字符串时,Redis会采用跳跃表来作为有序集合的底层实现。
具体设计
1 | // 跳跃表结构体如下 |
具体结构如下所示:
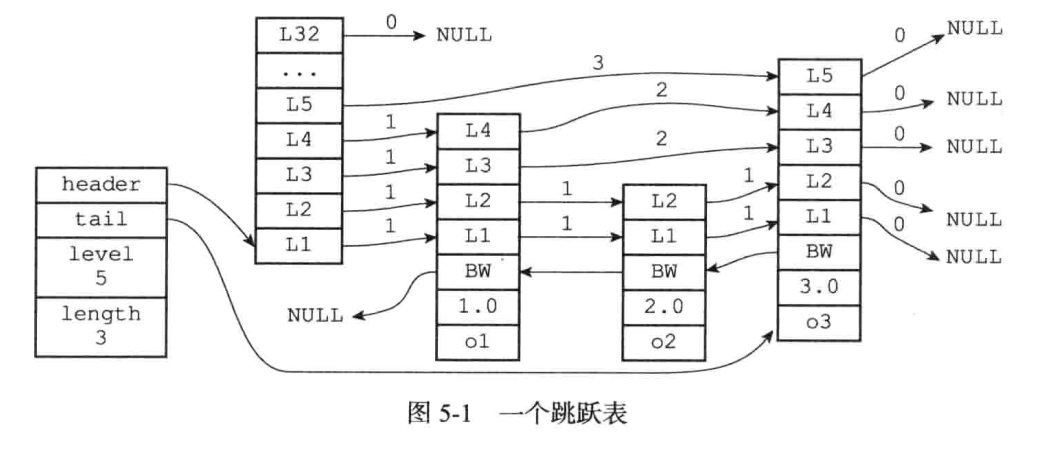
header:指向跳跃表的表头。
tail:指向跳跃表的表尾。
level:记录跳跃表内当前层数最大的那个层数。表头节点不算在内。
参考上面那个跳跃表,虽然有L32,但是L32没有数据。有数据的最深的的一层时L5,所以level的值为5。
length:记录跳跃表的长度,即目前跳跃表包含节点的数量。表头节点不计算在内。
注意:这里表头节点不计算在内,表头节点指的是header直接指向的节点。所以除了hader直接指向的节点,另外有3个节点,所以是3.
每一个节点,即L1,L2的构成:每一个小的节点就是skiplistNode中level数组中的一个。数组中每一个成员有一个前进指针以及跨度。前进指针用于指向尾节点方向的同一层的下一个节点。跨度指的是当前节点该层与指向下一个节点的距离,跨度越大,说明两个节点的距离越远。具体参考上图,指向线上的值就是跨度。
backward:用于从表尾向表头遍历时使用。
分值:在跳跃表中,数据按照各自的分值由小到大排列。
整数集合
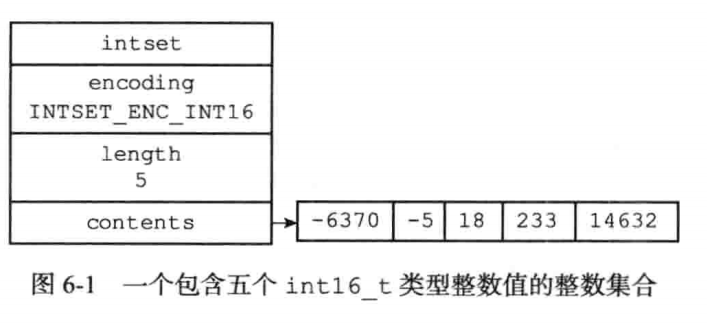
整数集合是Redis用于保存整数值的集合抽象数据结构。它可以用来保存int16_t, int32_t, int64_t。并且保证集合中不会出现重复值。
具体结构
1 | typedef struct intset { |
其中contents数组中的元素保存具体的数据,而且从小到达排列,并且没有重复值。
一个具体的例子:
升级
当我们向整数集合中添加一个元素时,如果该元素的类型比之前集合中所有元素类型都要大时,整数集合就需要升级。
升级的过程:
1)根据新元素的类型,扩展整数集合底层空间的大小,并且为新元素分配空间。
2)将整数集合中所有元素都转换为与新元素相同的类型。并将转换后的元素放在集合的原来位置。该过程需要与原来的顺序一致。
3)将新元素插入元素集合。
升级的优点
一方面提高数据的灵活性,另一方面节约内存。
压缩链表
使用场景
一个列表只包含少量列表项,并且列表项中的每个元素要么是小整数值,要么是比较短的字符串,Redis就会使用压缩列表来作为列表键的底层实现。
压缩列表的构成

zlbytes
该字段用于记录整个压缩列表占用的内存字节数。对压缩列表进行内存重分配,或者计算zlend的位置时使用。
zltail
记录压缩列表表尾节点距离压缩列表起始地址有多少字节,通过该变量可以由表头直接到达表尾。
zllen
记录了压缩列表中包含节点的数量。当这个值小于65535时,就是记录节点数量。但是大于65535,则需要遍历才能获取真证的节点数量。
entryX
代表具体的节点。节点长度由保存内容决定。
zlend
用于标记压缩列表的末端。
压缩列表每个节点的构成

previous_entry_length
该值代表了目前节点前一个节点的大小,如果前一个节点长度小于254字节,该值的长度就是1字节,如果大于或等于254字节,那么该值的长度就是5字节。
记录前一个字节的大小,可以方便倒序遍历。因为知道当前节点的起始位置,又知道前一个节点的大小,就可以算出前一个节点的位置。如果需要倒序遍历,我们可以通过zltail字段的值配合首地址,直接找到末尾节点的位置,然后通过每一个节点的前一个节点大小,进行倒序的遍历。
encoding
记录了节点的content属性所保存的数据类型以及长度。
content
负责保存节点的值。可以是一个字节数组或者整数。
连锁更新
考虑以下场景,如果有很多个连续的长度介于250-253字节的节点,因为这些节点的长度都小于254字节,所以他们的previous_entry_length属性大小都是1字节。但是现在新添加了一个节点,他的长度大于254,那么其中一个节点的previous_entry_length属性要更改为5字节,那么该节点自身的长度也就大于254,会导致它后边的节点也更新,最终导致这一连串的节点都需要重新分配内存。
而且删除节点时也有可能会导致这种情况。
实际使用中,很少会出现这种情况。
参考
《Redis设计与实现》