
Redis设计与实现之基本数据结构(二)
字典
具体结构
字典又称符号表、关联数组或映射,是一种用于保存键值对的抽象数据结构。
Redis字典使用哈希表作为底层实现,一个哈希表可以有多个哈希表节点,每一个哈希表节点保存了字典中的一个键值对。
1 | C |
Redis中的字典构造
1 | C |
一个字典的结构图如下所示
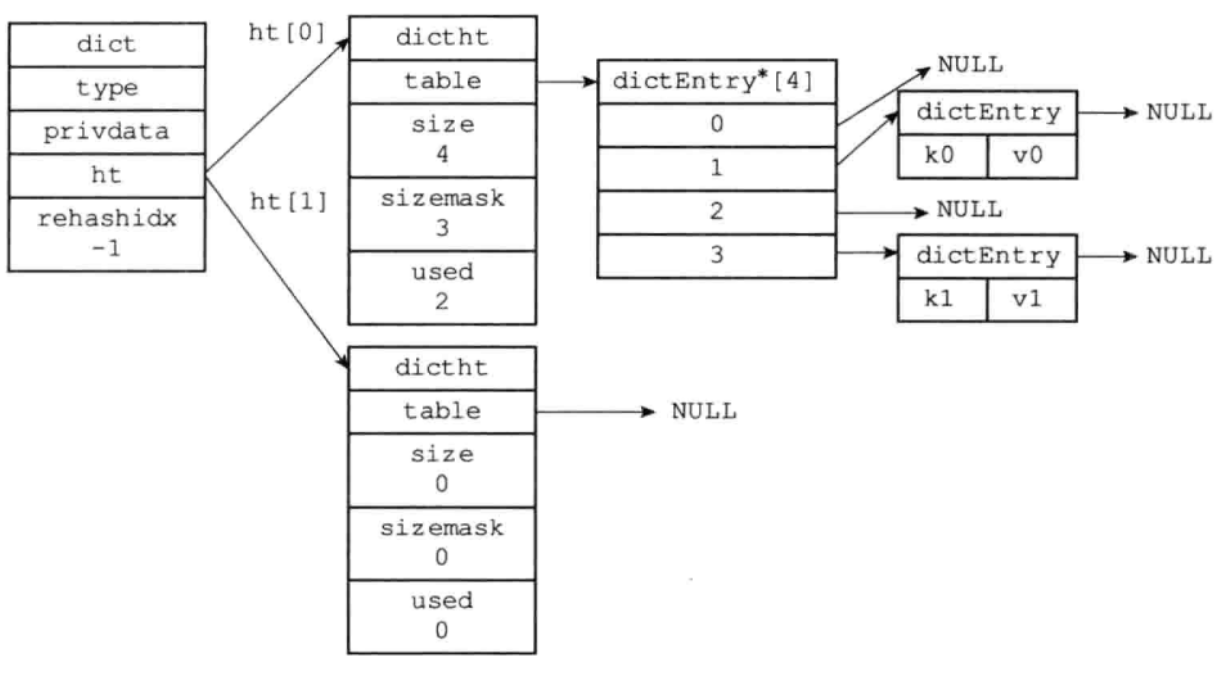
一个字典结构体,存储数据的是里面的ht,即一个哈希表数组,哈希表的大小为2。一个哈希表的主要内容是其中的table数组,用于存放键值对的数据结构。
哈希算法
当要将一个新的值插入数据字典时,要先根据键计算出哈希值和索引值,根据索引将新的键值对放到对应索引的位置。
这里计算出的索引就是dictht中table的下标,然后放入对应位置。
解决键冲突
Redis的哈希表使用链地址法解决键冲突(头插法)。每一个dictEntry都有一个指向下一个节点的指针,当出现冲突,就链接在后边。
Rehash
随着操作不断进行,哈希表保存的数据可能越来越多,也可能越来越少。为了保持哈希表的负载因子在一定范围内,当哈希表保存的键值对太多或太少时,哈希表会进行相应的扩容或者收缩。这个扩容或者收缩的过程就叫Rehash。
Rehash过程
1、首先是对ht[1]分配空间,如果是扩容操作,则大小为第一个大于ht[0].used * 2的2^n(n从0开始增大,一直到2^n大于used * 2 )。如果是收缩,则大小为第一个大于ht[0].used的2^n。
2、将ht[0]上的键值对重新计算哈希值,保存在ht[1]中。
3、当ht[0]的全部数据都重新计算哈希值并存入ht[1]后,释放ht[0]的空间,将ht[1]设置为ht[0],在ht[1]创建新的空白哈希表,用于下一次Rehash。
rehash条件
1、服务器没有执行BGSAVE命令,或者BGREWRITEAOF命令,且负载因子大于1。
2、在执行上述两个命令,且负载因子大于5。
负载因子计算方法:哈希表已保存节点数 / 哈希表大小
渐进式Rehash
Rehash将ht[0]所有值重计算放入ht[1]的过程并不是一次性,集中的完成的,而是分多次,渐进的完成的。
具体过程:
1、为ht[1]分配空间,让字典同时只有ht[0]和ht[1]两个哈希表。
2、字典中的rehashidx的值设置为0(初始值为-1),表示开始rehash。
3、在rehash期间,每次对字典进行增删改查时,还会顺带将 ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1]上,完成后将rehashidx的值增加1。
4、当ht[0]都被rehash到ht[1]上时,会将rehashidx的值设置为-1,表示rehash完成。
注意:rehash过程中,如果需要查找,删除,更新,则会在ht[0]和ht[1]中都进行操作,找到元素在哪就在那个表操作。如果进行插入,则只会在ht[1]表中进行。
参考
《Redis设计与实现》